|
E=mс2bedded
Pro |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Контакты: E-mail: embedded_pro@mail.ru AppNotes: Сотовая связь Отправка коротких SMS в
формате PDU Отправка длинных SMS в формате PDU Получение и декодирование
SMS Распределённые
вычислительные сети Обзор распределённых
вычислительных сетей Принципы построения распределённых вычислительных
сетей Встраиваемые решения Обзор
встраиваемых операционных
систем Обзор
микропроцессоров ARM
Cortex-A BSP QNX Neutrino
для платы phyFLEX-iMX6 от PHYTEC |
Главная / Принципы
построения распределённых вычислительных
сетей Принципы построения распределённых
вычислительных сетей 26 августа 1. Удаленный вызов процедур Remote Procedure Call, RPC 2.1. Заглушки для клиента и сервера 2.2. Передача параметров по значению 2.3. Передача параметров по ссылке 2.4. Спецификация параметров и генерация заглушек 2.5. Вызов RPC 3.1. Обращение к удаленным объектам в DCE 4.1. Алгоритм Кристиана 4.2. Алгоритм Беркли 5. Распределённое подтверждение 5.1. Протокол двухфазного подтверждения Two-phase Commit Protocol, 2PC 5.2. Трехфазное подтверждение Three-phase Commit Protocol, 3РС 6. Работа RPC при наличии ошибок 6.1. Клиент не в состоянии обнаружить сервер 6.2. Потеря сообщения с запросом 6.3. Поломка сервера 6.4. Потеря ответного сообщения 6.5. Поломка клиента 7. Надежная групповая рассылка. Базовые схемы надежной
групповой рассылки 7.1. Неиерархическое управление обратной связью 7.2. Иерархическое управление обратной связью 8. Распределённая
система Jini 8.1.
Примечание 8.2. Модель согласования 8.3. Архитектура 8.4. Связь 8.5. Процессы 8.6. Именование 8.6.1. Служба поиска Jini 8.6.2. Аренда 8.6.3. Синхронизация 8.6.4. Транзакции Данная
статья является выжимкой из книги Эндрю Таненбаума
«Распределённые системы. Принципы и парадигмы». Книга достаточно объёмная,
содержащая 900 страниц, и посвящена, как следует из названия, общим принципам
построения распределённых вычислительных систем. Статья
содержит лишь переработанную часть информации, приведённой в книге, а именно
ту часть, которая посвящена построению распределённых систем на основе
удалённого вызова процедур RPC, метода,
наиболее удовлетворяющего задачам построения распределённой системы объекта
разработки, описанного в предыдущих документах. Так же в
статье в качестве примера построения распределённой системы описывается система Jini
компании Sun Microsystems. Остальные
модели взаимодействия в распределённых системах, такие как удаленное обращение к методам (Remote Method Invocation, RMI), ориентированный на сообщения
промежуточный уровень (Message-Oriented Middleware, MOM) и потоки данных (Streams) в данной статье не рассматриваются,
т.к. по мнению автора статьи являются либо
невостребованными, как например модели MOM и Streams, либо обладающими избыточной
сложностью, как например модель RMI. Не предполагается стопроцентное
применение в разработке методов, описанных в книге. Анализ принципов
устройства распределённых систем будет полезен с точки зрения выхода из
кризисных ситуаций в процессе построения распределённой системы объекта
разработки. 1. Удаленный вызов процедур Remote Procedure Call, RPC. Основой множества распределенных
систем является явный обмен сообщениями между процессами. Однако процедуры
типа send и receive не
скрывают взаимодействия, что необходимо для обеспечения прозрачности доступа.
В связи с этим предложено позволить программам вызывать процедуры,
находящиеся на других машинах. Когда процесс, запущенный на машине А, вызывает процедуру с машины Б, вызывающий процесс на
машине А приостанавливается,
а выполнение вызванной процедуры происходит на машине Б. Информация может быть передана от вызывающего процесса к
вызываемой процедуре через параметры и возвращена процессу в виде результата
выполнения процедуры. Для программиста данный процесс становится абсолютно
прозрачным. Этот метод известен под названием удаленный вызов процедур (Remote Procedure Call, RPC). Базовая идея проста, но сложности
возникают при реализации. Поскольку вызывающий процесс и вызываемая процедура
находятся на разных машинах, они выполняются в различных адресных
пространствах, что тут же рождает проблемы. Параметры и результаты также
передаются от машины к машине, что может вызвать свои затруднения, особенно
если машины не одинаковы. Наконец, обе машины могут сбоить, и любой возможный
сбой вызовет разнообразные сложности. Однако с большинством из этих проблем
можно справиться, и RPC является широко
распространенной технологией, на которой базируются многие распределенные
системы. 2.1. Заглушки для клиента и
сервера. Идея, стоящая за RPC, состоит в
том, чтобы удаленный вызов процедур выглядел точно так же, как и локальный,
то есть был прозрачным и вызывающая процедура не должна уведомляться о том,
что вызываемая процедура выполняется на другой машине, и наоборот. RPC организует свою прозрачность
следующим образом. Если стандартная функция чтения read
предназначена для чтения локального блока данных или файла, то для функции read, которая является удаленной процедурой (то есть
будет исполняться на машине файлового сервера), создаётся специальная специальная версия read, называемая клиентской
заглушкой (client stub). Как
и оригинальная функция, она вызывается и сама производит вызов локальной операционной
системы, только в отличие от оригинальной функции клиентская заглушка не
запрашивает данные у операционной системы. Вместо
этого она упаковывает параметры в сообщение и путем вызова процедуры send требует переслать это сообщение на сервер. После
вызова процедуры send клиентская заглушка вызывает
процедуру receive, блокируясь до получения ответа. Когда сообщение приходит на
сервер, операционная система сервера передает его серверной заглушке (server stub). Серверная заглушка
эквивалентна клиентской, но работает на стороне сервера. Это фрагмент
кода, который преобразует приходящие по сети запросы в вызовы локальных
процедур. Обычно серверная заглушка запускает процедуру receive
и блокируется, ожидая входящих сообщений. После получения сообщения серверная
заглушка распаковывает его, извлекая параметры, и традиционным способом
вызывает процедуру сервера. С точки зрения сервера это воспринимается как
прямой вызов с клиента - параметры и адрес возврата находятся в стеке, где
они и должны находиться, и ничего необычного в этом нет. Сервер делает своё
дело и обычным порядком возвращает результат вызвавшей процедуре. Когда серверная заглушка после
окончания обработки вызова возвращает управление вызвавшей программе, она
запаковывает результаты выполнения в сообщение и вызывает процедуру send, чтобы возвратить их клиенту. После этого серверная
заглушка вновь вызывает процедуру receive, переходя
в режим ожидания следующего сообщения. Когда на клиентскую машину
приходит ответное сообщение, операционная система клиента обнаруживает, что
оно адресовано клиентскому процессу (на самом деле клиентской заглушке, но
операционная система их не различает). Сообщение копируется в буфер
ожидания, и клиентский процесс разблокируется.
Клиентская заглушка рассматривает сообщение, распаковывает его, извлекая
результаты, копирует их в память вызвавшей программы и, завершая работу,
передаёт в неё код возврата. Когда вызвавшая программа получает управление
после вызова read, всё, что она знает, - это то,
что запрошенные данные находятся там, где и предполагалось, то есть в буфере.
У неё нет никакого представления о том, как осуществлялся вызов - удалённо
или в рамках локальной операционной системы. Именно в том, что ПО клиента не
имеет информации о масштабах выполненного алгоритма, и заключается
преимущество такой схемы. Доступ к удаленным службам
осуществляется посредством вызова обычных для ПО клиента процедур. Все
детали пересылки сообщений скрыты в двух библиотечных процедурах, так же как
в традиционных библиотеках скрыты детали реально производимых системных
вызовов. Таким образом, при удалённом
вызове процедур происходят следующие действия: Процедура
клиента обычным образом вызывает клиентскую заглушку. Клиентская
заглушка создает сообщение и вызывает локальную операционную систему. Операционная
система клиента пересылает сообщение удалённой операционной системе. Удалённая
операционная система передаёт сообщение серверной заглушке. Серверная
заглушка извлекает из сообщения параметры и вызывает сервер. Сервер выполняет
вызов и возвращает результаты заглушке. Серверная заглушка запаковывает
результаты в сообщение и вызывает свою локальную операционную систему. Операционная
система сервера пересылает сообщение операционной системе клиента. Операционная
система клиента принимает сообщение и передаёт его клиентской заглушке. Заглушка
извлекает результаты из сообщения и передаёт их клиенту. Сетевые эффекты этих шагов состоят
в том, что клиентская заглушка превращает локальный вызов процедуры клиента в
локальный вызов процедуры сервера, причём ни клиент, ни сервер ничего не
знают о промежуточных действиях. Назначение клиентской заглушки
состоит в том, чтобы получить параметры, запаковать их в сообщение и послать
его серверной заглушке. 2.2.
Передача параметров по значению. Упаковка параметров в сообщение
носит название маршалинга параметров. При
вызове удалённой процедуры происходит следующее. Клиентская заглушка извлекает два
параметра процедуры и упаковывает их в сообщение. Она также помещает туда имя
или номер вызываемой в сообщении процедуры, поскольку сервер может
поддерживать несколько разных процедур и ему следует указать, какая из них
потребовалась в данном случае. Когда сообщение приходит на
сервер, серверная заглушка исследует сообщение в поисках указания на то,
какую процедуру следует вызвать, а затем делает соответствующий вызов. Если
сервер поддерживает и другие удаленные процедуры, серверная заглушка должна
содержать конструкцию типа switch для выбора
вызываемой процедуры в зависимости от первого поля сообщения. Реальный вызов
процедуры сервера из серверной заглушки выглядит почти как первоначальный
клиентский вызов, если не считать того, что параметрами являются переменные,
инициализированные значениями, взятыми из сообщения. Таким образом, имеет место
следующая пошаговая процедура: Клиент
вызывает удалённую процедуру. Клиентская
заглушка строит сообщение. Сообщение
отправляется по сети на сервер. Операционная
система сервера передаёт сообщение серверной заглушке. Серверная
заглушка распаковывает сообщение. Серверная
заглушка выполняет локальный вызов процедуры. Когда сервер заканчивает работу,
управление вновь передается серверной заглушке. Она получает результат,
переданный сервером, и запаковывает его в сообщение. Это сообщение
отправляется назад, к клиентской заглушке, которая распаковывает его и
возвращает полученное значение клиентской процедуре. До тех пор пока машины клиента и
сервера идентичны, а все параметры и результаты имеют скалярный тип (то есть
целый, символьный или логический), эта модель работает абсолютно правильно.
Однако в больших распределённых системах обычно присутствуют машины разных
типов. Каждая из машин часто имеет собственное представление чисел, символов
и других элементов данных. Это приводит к конфликту типов данных, и конфликт
этот требует разрешения. 2.3.
Передача параметров по ссылке. Ещё одной проблемой является
передача удалённым процедурам указателей на данные или, в общем случае,
ссылок. Указатель имеет смысл только в адресном пространстве того процесса, в
котором он используется. Одно из решений состоит в том,
чтобы скопировать массив, на который указывает указатель, в сообщение и
передать его на сервер. Серверная заглушка может после этого вызвать сервер,
передав ему указатель на этот массив, даже если
числовое значение этого указателя будет отличаться от переданного. Изменения,
которые с помощью указателя сделает сервер (то есть по указанному адресу
запишет данные), прямо отразятся на буфере сообщения серверной заглушки.
Когда сервер закончит работу, оригинальное сообщение будет отослано назад,
клиентской заглушке, которая скопирует буфер клиенту. В результате вызов по
ссылке будет подменен копированием/восстановлением. Несмотря на то что это не одно и то же, часто такой замены вполне
достаточно. Небольшая оптимизация позволяет
сделать этот механизм вдвое эффективнее. Если обеим заглушкам известно,
входящим или исходящим параметром является буфер для сервера, то одну из
копий можно удалить. Если массив используется сервером в качестве исходных
данных, то копировать его обратно не нужно. Если это результат, то нет
необходимости изначально передавать его серверу. В качестве последнего комментария
отметим, что нет ничего особенно хорошего в том, что мы можем работать с
указателями на простые массивы и структуры, если нам по-прежнему недоступна
работа с более общими вариантами указателей - с
указателями на произвольные структуры данных, например на сложные графы. В
некоторых системах делается попытка решить эту проблему путем передачи
серверной заглушке реальных указателей с последующей генерацией специального
кода в процедурах сервера для работы с этими указателями. Так, для получения
данных, которые соответствуют указателю, сервер может сделать специальный
запрос. 2.4. Спецификация параметров и
генерация заглушек. Сокрытие механизма удаленного
вызова процедур требует, чтобы вызывающая и вызываемая системы договорились о
формате сообщений, которыми они обмениваются, и при необходимости пересылки,
например, данных сложной структуры, следовали определенному порядку действий.
Другими словами, при совершении RPC обе стороны должны следовать одному
протоколу. Определение формата сообщения это
одна сторона протокола RPC. Но этого недостаточно. Также
необходимо, чтобы клиент и сервер пришли к договоренности по вопросу
представления простых типов данных, таких как целые числа, символы,
логические значения и т. д. Так, протокол может предписать, чтобы целые
передавались без знака, символы в 16-битной кодировке Unicode,
а числа с плавающей точкой — в формате стандарта IEEE 754, и все это – в
формате Intel, т.е. младшими байтами вперёд.
Только при наличии такой дополнительной информации сообщение может быть
однозначно интерпретировано. После того как все биты до
последнего выстроены в ряд по согласованным правилам кодирования, вызывающая и вызываемая системы должны договориться между
собой об обмене реальными сообщениями. Например, они могут решить
использовать транспортный протокол с соединениями, такой как TCP/IP. После
завершения определения протокола RPC необходимо реализовать заглушки -
клиентскую и серверную. Заглушки, работающие по одному протоколу, для разных
процедур различаются лишь интерфейсом с приложениями. Интерфейс состоит из набора
процедур, которые могут быть вызваны клиентом, но реализуются на сервере.
Доступ к интерфейсу осуществляется обычно из определенного языка
программирования, одного из тех, на которых написан клиент или сервер. Для
упрощения работы интерфейсы часто описываются с использованием языка определения интерфейсов (Interface Definition Language, IDL). Интерфейс, определённый на чём-то вроде
IDL, компилируется затем в заглушки клиента и сервера, а также в
соответствующие интерфейсы времени компиляции и времени выполнения. Практика показывает, что
использование языка определения интерфейсов делает приложения клиент-сервер,
базирующиеся на RPC, существенно проще. Поскольку клиентскую и серверную
заглушки очень легко сгенерировать полностью автоматически, все системы
промежуточного уровня, основанные на RPC, используют IDL для поддержки
разработки программного обеспечения. В некоторых случаях применение IDL
просто обязательно. В стандартном варианте вызова
клиентом удаленной процедуры его работа приостанавливается до получения
ответа. Когда ответ не нужен, этот жесткий алгоритм «запрос-ответ» не
является необходимым, приводя только к блокированию клиента с невозможностью
производить работу до получения ответа от удаленной процедуры. Примеры
действий, при которых обычно нет необходимости в ожидании ответа:
перечисление денег с одного банковского счета на другой, добавление записей в
базу данных, запуск удаленной службы, пакетная обработка и множество других. Для обработки подобных случаев
системы RPC могут предоставлять средства для так называемого асинхронного вызова RPC (asynchronous RPC). При помощи этих средств клиент получает возможность продолжить свою работу
сразу после выполнения запроса RPC. При асинхронном вызове RPC сервер
немедленно по приходу запроса отсылает клиенту ответ, после чего вызывает
запрошенную процедуру. Ответ служит подтверждением того, что сервер приступил
к обработке RPC. Клиент продолжает работу, снимая блокировку, сразу
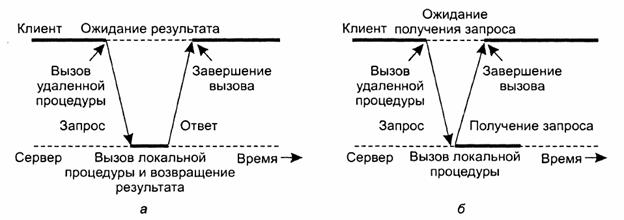
после получения от сервера этого подтверждения. На рис. 1а приведен
стандартный алгоритм взаимодействия «запрос-ответ», а на рис. 1б - алгоритм взаимодействия клиента
и сервера в случае асинхронного вызова RPC.
Рис. 1. Взаимодействие между
клиентом и сервером в RPC традиционной схемы (а). Взаимодействие с
использованием асинхронного вызова RPC (б) Асинхронные вызовы RPC также могут
быть полезны в тех случаях, когда ответ будет послан, но клиент не готов
просто ждать его, ничего не делая. Например, клиент может пожелать заранее
выбрать сетевые адреса из набора хостов, с которыми вскоре будет связываться.
В то время, пока служба именования соберёт эти адреса, клиент может заняться
другими вещами. В подобных случаях имеет смысл организовать сообщение между
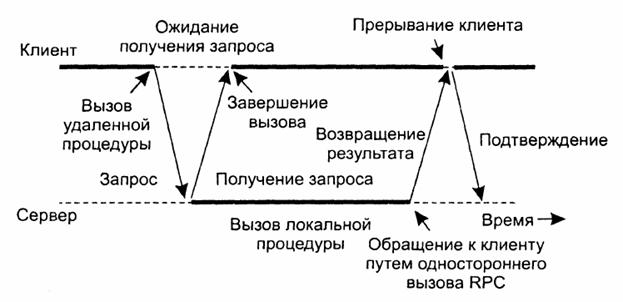
клиентом и сервером через два асинхронных вызова RPC, как это показано на
рис. 2. Сначала клиент вызывает сервер, чтобы передать ему список имён
хостов, который следует подготовить, и продолжает свою работу, когда сервер
подтверждает получение этого списка. Второй вызов делает сервер, который
вызывает клиента, чтобы передать ему найденные адреса. Комбинация из двух
асинхронных вызовов RPC иногда называется также отложенным синхронным вызовом RPC (deferred
synchronous RPC).
Рис.
2. Взаимодействие клиента и сервера посредством двух асинхронных вызовов RPC Следует отдельно отметить вариант
асинхронного вызова RPC, реализующегося в тех случаях, когда клиент
продолжает работу немедленно после посылки запроса на сервер. Другими
словами, клиент не ожидает от сервера подтверждения в получении запроса.
Такие вызовы называются односторонними
вызовами RPC (one-way RPC). Проблема такого подхода состоит в
том, что при отсутствии гарантий надежности передачи клиент не может быть
точно уверен, что его запрос будет выполнен. 3. Модель распределенных объектов распределённой
вычислительной среды (Distributed Computing Environment, DCE). Распределенные объекты имеют вид
удаленных объектов распределённой
вычислительной среды DCE, реализация которых находится на
сервере. Сервер отвечает за локальное создание объектов и обеспечение доступа
к их методам с удаленных клиентских машин. Других способов создания
распределенных объектов не существует. Поддерживаются два типа
распределенных объектов.
Динамические распределенные объекты (distributed dynamic objects) это
объекты, которые создаются сервером локально по требованию клиента и к
которым в принципе имеет доступ только один клиент. Для создания такого
объекта сервер должен получить запрос от клиента. Это означает, что каждый
класс, чтобы иметь возможность создавать динамические объекты, должен
содержать процедуру create, которую можно вызвать,
используя стандартный механизм RPC. После создания динамического объекта
управление им переходит к исполняющей системе DCE, связывающей его с тем
клиентом, по требованию которого он был создан. В противоположность динамическим
объектам, именованные распределённые
объекты (distributed named
objects) не предназначены для работы с
единственным клиентом. Они создаются сервером для совместного использования несколькими клиентами.
Именованные объекты регистрируются службой каталогов, так что клиент может
найти объект и выполнить привязку к нему. Регистрация означает сохранение
уникального идентификатора объекта, а также информации о том, как соединиться
с сервером объекта. 3.1. Обращение к удаленным
объектам в DCE. Как можно заметить, все обращения
к удаленным объектам в DCE производятся средствами RPC. Клиент, обращаясь к
методу, передает серверу идентификатор объекта, идентификатор интерфейса,
содержащего метод, идентификацию самого метода и параметры. Сервер
поддерживает таблицу объектов. С помощью этой таблицы сервер, получив
идентификатор объекта и идентификатор интерфейса, идентифицирует объект, к
которому обратился клиент. Затем он выбирает запрошенный метод и передает ему
параметры. Поскольку сервер может поддерживать тысячи объектов, DCE
предоставляет возможность не держать все объекты в памяти, а помещать их при
необходимости во вспомогательное хранилище данных. Когда к серверу приходит
запрос на обращение к объекту, отсутствующему в таблице объектов, исполняющая
система может вызвать специализированную функцию поиска, которая извлечет
объект из хранилища и поместит его в адресное пространство сервера. Обращение
к объекту произойдет после его помещения в оперативную память. У распределенных объектов в DCE
имеется одна проблема, связанная с их чрезвычайной близостью с RPC: не
существует механизма прозрачных ссылок на объекты. Клиент имеет в лучшем
случае дескриптор привязки (binding handle), ассоциированный
с именованным объектом. Дескриптор привязки содержит идентификатор
интерфейса, транспортный протокол, используемый для связи с сервером
объектов, а также адрес и конечную точку хоста сервера. Дескриптор привязки
может быть преобразован в строку и в таком виде передан другому процессу. Отсутствие приемлемого механизма
ссылок на объекты в пределах системы делает передачу параметров в DCE более
сложной, чем в большинстве объектных систем. Разработчик приложений для RPC должен сам придумывать механизм передачи
параметров. На деле это означает, что необходимо явно производить маршалинг объектов для передачи их по значению и
самостоятельно создавать для этого соответствующие процедуры. В качестве альтернативы
разработчик может использовать делегирование. Для этого из спецификации
интерфейса объекта генерируется специальная заглушка. Заглушка работает как
оболочка нужного объекта и содержит только те методы, которые будут
вызываться удаленными процессами. Заглушка может быть скомпонована с любым
процессом, который хочет использовать этот объект. Преимущества такого подхода
становятся понятны, если вспомнить, что DCE разрешает передавать удаленные
ссылки на заглушки в качестве параметров вызовов RPC. Соответственно, появляется
возможность ссылаться на объекты системы при помощи ссылок на заглушки. Данный алгоритм хорошо подходит
для систем, в которых один из узлов (сервер времени) имеет возможность
точного выставления своих часов, а наша задача состоит в синхронизации всех
остальных узлов. Периодически, гарантировано не реже, чем каждые δ/2ρ секунд, где δ
– установленный для узла максимальный дрейф времени, ρ
– технически определённый дрейф часов, каждый узел посылает серверу времени
сообщение, запрашивая текущее время. Сервер отвечает сообщением, содержащим
его текущее время. В качестве первого приближения,
когда отправитель получает ответ, он может просто выставить свои часы в
полученное значение. Однако
такой алгоритм имеет две проблемы: главную и второстепенную. Главная проблема
состоит в том, что время никогда не течет назад. Если часы отправителя
спешат, то полученное от сервера время может оказаться меньше текущего
значения времени у отправителя. Простая подстановка времени сервера способна
вызвать серьезные проблемы, связанные с тем, например, что объектные файлы,
скомпилированные после того, как было изменено время, становятся
помечены временем более ранним, чем модифицированные исходные тексты, которые
поправлялись до изменения времени, что может привести к невозможности
дальнейшей трансляции исходных кодов. Для решения этой проблемы
изменения могут вноситься постепенно. Предположим, что таймер узла, на
котором производится синхронизация времени, настроен так, что он генерирует
100 прерываний в секунду. В нормальном состоянии каждое прерывание будет
добавлять ко времени по 10 мс. При запаздывании часов сервера процедура
прерывания будет добавлять каждый раз всего по 9 мс. Соответственно, часы
должны быть исправлены так, чтобы добавлять при каждом прерывании 9 мс. Менее серьезная проблема состоит в
том, что перенос ответного сообщения с сервера времени отправителю требует
ненулевого времени. Хуже всего, что эта задержка может быть весьма велика и зависеть от загрузки сети. Метод решения проблемы состоит
в измерении этой величины. Отправителю достаточно просто аккуратно записать
интервал между посылкой запроса и приходом ответа. То и другое время
измеряется по одним и тем же часам, а значит, интервал будет относительно
точно измерен даже в том случае, если часы отправителя имеют некоторое
расхождение с UTC. В отсутствии какой-либо дополнительной информации
наилучшим приближением времени прохождения сообщения будет половина разницы
между временем отправки запроса и получения ответа. После получения ответа, чтобы получить приблизительное
текущее время сервера, значение, содержащееся в сообщении, следует увеличить
на это число. Эта оценка может быть улучшена, если приблизительно известно,
сколько времени сервер времени обрабатывает прерывание и работает с пришедшим
сообщением. Для повышения точности Кристиан предложил производить не одно измерение, а
серию. Все измерения, в которых время доведения превосходит некоторое
пороговое значение, отбрасываются как ставшие жертвами перегруженной сети, а
потому недостоверные. Оценка делается по оставшимся замерам, которые могут
быть усреднены для получения наилучшего значения. С другой стороны,
сообщение, пришедшее быстрее всех, можно рассматривать как самое точное,
поскольку оно предположительно попало в момент наименьшего трафика
и потому наиболее точно отражает чистое время прохождения. В алгоритме Кристиана
сервер времени пассивен. Прочие машины периодически запрашивают у него время.
Все, что он делает, - это отвечает на запросы. В операционной системе UNIX
разработки университета Беркли (Berkeley) принят
прямо противоположный подход. Здесь сервер времени активен, он время от
времени опрашивает каждую из машин, какое время на её часах. На основании
ответов он вычисляет среднее время и предлагает всем машинам установить их
часы на новое время или замедлить часы, пока не будет достигнуто необходимое
уменьшение значения времени на сильно ушедших вперед часах. Этот метод
применим для систем, не имеющих выхода на глобальные часы. Время сервера
может периодически выставляться оператором Оба ранее описанных алгоритма
сильно централизованы с неизбежно вытекающими отсюда недостатками. Известны
также и децентрализованные алгоритмы. Один из классов алгоритмов
децентрализованной синхронизации часов работает на основе деления времени на
синхронизационные интервалы фиксированной продолжительности. В начале каждого
интервала каждый узел производит широковещательную рассылку значения текущего
времени на своих часах. Поскольку часы на различных машинах идут с немного
различной скоростью, эти широковещательные рассылки будут сделаны не
одновременно. После рассылки машиной своего времени она запускает локальный
таймер и начинает собирать все остальные широковещательные пакеты в течение
некоторого интервала. Когда будут собраны все широковещательные пакеты,
запускается алгоритм вычисления по ним нового времени. Простейший алгоритм
состоит в усреднении значений всех остальных машин. Незначительные его
вариации заключаются, во-первых, в отбрасывании самых больших и самых
маленьких значений и усреднении оставшихся. Отбрасывание крайних значений
можно рассматривать как самозащиту от неправильных часов. Другая вариация состоит в том,
чтобы попытаться скорректировать каждое из сообщений, добавляя к ним оценку
времени прохождения от источника. Эта оценка может быть сделана на основе знания
топологии сети или измерением времени прохождения эха. 5. Распределённое подтверждение. Задача распределенного
подтверждения (distributed
commit) включает в себя операции,
производимые либо с каждым членом группы процессов, либо ни с одним из них. В
случае надежной групповой рассылки операцией будет доставка сообщения. В
случае распределенных транзакций операцией будет подтверждение транзакции на
одном из сайтов, задействованных в транзакции. Распределённое подтверждение часто
организуется при помощи координатора. В простой схеме координатор сообщает
всем остальным процессам, которые также участвуют в работе (они называются
участниками), в состоянии ли они локально осуществить запрашиваемую операцию.
Эта схема известна под названием протокола
однофазного подтверждения (one-phase commit protocol). Он
обладает одним серьёзным недостатком. Если один из участников на самом деле
не может осуществить операцию, он не в состоянии сообщить об этом
координатору. Так, например, в случае распределённых транзакций локальное
подтверждение может оказаться невозможным из-за того, что оно будет нарушать
ограничения управления параллельным выполнением. Для практического применения
необходима более сложная схема. Обычно используется протокол двухфазного
подтверждения, который детально рассматривается ниже. Основной его недостаток
состоит в том, что он не в состоянии эффективно справляться с ошибками
координатора. Поэтому был разработан протокол трехфазного подтверждения. 5.1. Протокол двухфазного
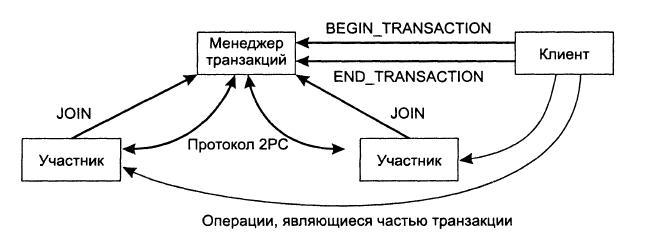
подтверждения Two-phase Commit Protocol, 2PC. Рассмотрим распределённую
транзакцию, предполагающую участие множества процессов, каждый из которых
работает на отдельной машине. Если предположить, что ошибки отсутствуют,
протокол состоит из следующих двух фаз, каждая из которых включает в себя два
шага: Координатор рассылает всем
участникам сообщение VOTE_REQUEST. После того как участник получит
сообщение VOTE_REQUEST, он
возвращает координатору либо сообщение VOTECOMMIT,
указывая, что он готов локально подтвердить свою часть транзакции,
либо сообщение VOTEABORT в противном
случае. Координатор собирает ответы
участников. Если все участники проголосовали за подтверждение транзакции,
координатор начинает осуществлять соответствующие действия и посылает всем
участникам сообщение GLOBAL_COMMIT. Однако
если хотя бы один участник проголосовал за прерывание транзакции, координатор
принимает соответствующее решение и рассылает сообщение GLOBAL_ABORT. Каждый из участников,
проголосовавших за подтверждение, ожидает итогового решения координатора.
Если участник получает сообщение GLOBAL_COMMIT,
он локально подтверждает транзакцию. В случае же получения сообщения GLOBAL_ABORT транзакция локально
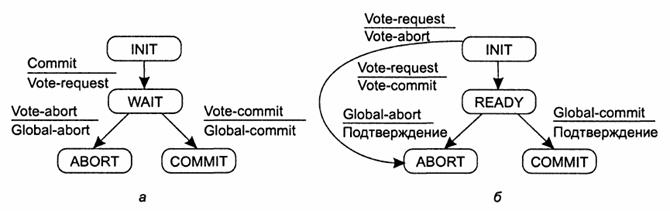
прерывается. Первая фаза (фаза голосования)
состоит из шагов 1.1 и 1.2, вторая (фаза решения) - из шагов 2.1 и 2.2. Эти
четыре шага показаны на диаграмме конечного автомата (рис. 3).
Рис. 3. Координатор в протоколе 2РС в виде
конечного автомата (а). Участник в виде конечного автомата (б). Когда при использовании базового
протокола 2РС в системе появляются ошибки, возникают определённые проблемы. В
первую очередь, отметим, что как координатор, так и участники имеют такие состояния,
в которых они блокируются и ожидают прихода сообщений. Соответственно, если
процесс отказывает, работа протокола легко может быть нарушена, поскольку
другие процессы будут бесконечно ожидать от него сообщения. По этой причине
вводятся механизмы тайм-аута. Глядя на конечные автоматы,
представленные на рисунке, можно заметить, что всего существует три
состояния, в которых координатор или участник могут, будучи заблокированными,
ожидать прихода сообщения. Во-первых, участник может, находясь в начальном
состоянии INIT, ожидать
сообщения VOTE_REQUEST от
координатора. Если в течение некоторого времени этого сообщения нет, участник
приходит к выводу о необходимости локального прерывания транзакции и посылает
координатору сообщение VOTE_ABORT. Точно так же координатор,
блокированный в состоянии WAIT, ожидает
прихода голосов всех участников. Если в течение некоторого времени не будут
собраны все голоса, координатор решает, что транзакцию необходимо прервать, и
рассылает всем участникам сообщение GLOBAL_ABORT. И, наконец, участник может быть
блокирован в состоянии READY, ожидая
глобального объявления результатов голосования, рассылаемого координатором.
Если это сообщение за определенный период времени не приходит, участник не
может просто решить прервать транзакцию. Вместо этого он должен определить,
какое же сообщение на самом деле посылал координатор. Самым простым решением
этого вопроса будет блокировка участника до момента восстановления
координатора. Более правильным решением будет
разрешить участнику Р контакт с другим участником, Q,
чтобы он мог по текущему состоянию Q
решить, что же ему делать дальше. Так, например, пусть Q перешел в состояние COMMIT. Это возможно только в том
случае, если координатор до поломки послал Q сообщение GLOBAL_COMMIT. Видимо, до Р это сообщение не дошло.
Соответственно, Р теперь может прийти к выводу о
необходимости локального подтверждения. Точно так же если Q находится в
состоянии ABORT, Р
может уверенно прерывать свою часть транзакции. Теперь предположим, что Q
пребывает в состоянии INIT. Такая
ситуация может произойти, если координатор разошлет всем участникам сообщения
VOTE_REQUEST и это сообщение
дойдет до Р (который ответит на него посылкой
сообщения VOTE_COMMIT), но не
дойдет до Q. Другими словами, координатор может отказать во время рассылки
сообщения VOTE_REQUEST. В
этом случае правильно будет прервать транзакцию: и Р,
и Q могут осуществлять переход в состояние ABORT. Наиболее сложную ситуацию мы
получим, если Q также будет находиться в состоянии READY, ожидая ответа от координатора. Так, если окажется, что
все участники находятся в состоянии READY,
конкретное решение принять невозможно. Проблема состоит в том, что все
участники готовы подтвердить транзакцию, но для этого им необходим голос
координатора. Соответственно, протокол блокируется до момента восстановления
координатора. Чтобы гарантировать, что процесс
действительно восстановился, нужно чтобы он сохранял свое состояние при
помощи средств длительного хранения данных. Так,
например, если участник находился в состоянии INIT, то после восстановления он может решить локально
прервать транзакцию и сообщить об этом координатору. Точно так же если он уже
принял решение и в момент поломки находился в состоянии COMMIT или ABORT, то при восстановлении он снова придёт в выбранное
состояние и повторно сообщит свое решение координатору. Проблемы возникают, когда участник
отказывает, находясь в состоянии READY.
В этом случае при восстановлении он не может определить на основании
собственной информации, что делать дальше, завершать или прерывать
транзакцию. Соответственно, чтобы выяснить, что делать этому процессу, его
следует заставить связаться с другими участниками, как это проделывалось в
ситуации истечения тайм-аута в состоянии READY, описанной ранее. Координатор имеет только два
критических состояния, за которыми надо следить. Когда он начинает протокол
2РС, он должен сохранить сведения о том, что он находится в начальном
состоянии WAIT, чтобы иметь
возможность при необходимости после восстановления повторно разослать
сообщение VOTE_REQUEST всем
участникам. Кроме того, если в ходе второй фазы он принял решение, следует
сохранить это решение, чтобы после восстановления координатора его также
можно было разослать повторно. Возможна
ситуация, когда участнику придется установить блокировку до восстановления
координатора. Такая ситуация может возникнуть, если все участники получат и
обработают сообщение координатора VOTE_REQUEST
и в ходе этой работы координатор сломается. В этом случае участники не
смогут совместно решить, какое действие им предпринять. По
этой причине протокол 2PC также называют протоколом блокирующего подтверждения {blocking
commit protocol). Существует
несколько способов избежать блокировки. Одно из них состоит в использовании
примитива групповой рассылки, когда получатель немедленно рассылает ответное
сообщению всем остальным процессам. Можно показать, что подобный подход
позволяет участнику принять итоговое решение даже в том случае, если
координатор еще не восстановился. Другое решение - использование протокола
трехфазного подтверждения. 5.2. Трехфазное подтверждение Three-phase Commit Protocol, 3РС. Проблема
протокола двухфазного подтверждения состоит в том, что при поломке
координатора участники могут оказаться не в состоянии прийти к итоговому
решению. В результате участникам приходится дожидаться восстановления
координатора, находясь в заблокированном состоянии. Существует вариант
протокола 2PC, названный протоколом
трехфазного подтверждения (Three-phase Commit Protocol, 3РС), который
предотвращает блокировку процессов при появлении ошибок аварийной остановки.
Хотя протокол 3РС часто упоминается в литературе, на практике он используется
редко, потому что редко возникают условия, в которых блокируется 2РС. Данный
протокол представляет собой дальнейшее развитие решений проблем
отказоустойчивости в распределенных системах. Как и
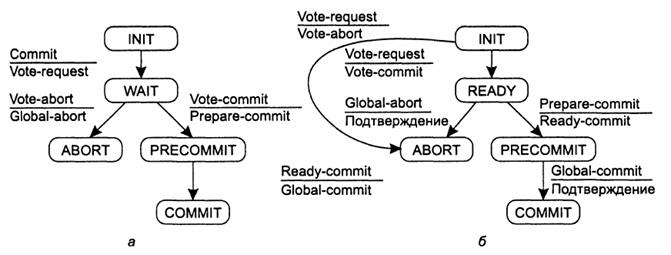
2РС, 3РС формулируется в терминах координатора и набора участников.
Соответствующие им конечные автоматы показаны на рис. 4. Сущность протокола
состоит в том, что состояния координатора и любого из участников
удовлетворяют двум условиям: не
существует такого состояния, из которого может быть осуществлен прямой
переход как в состояние COMMIT, так
и в состояние ABORT; не
существует такого состояния, в котором невозможно принять итоговое решение,
но возможен переход в состояние COMMIT. Эти два
условия необходимы и достаточны для того, чтобы протокол подтверждения был неблокирующим.
Рис. 4.
Координатор в протоколе 3РС в виде конечного автомата (а). Участник в виде
конечного автомата(б) Координатор
3РС начинает с рассылки всем участникам сообщения VOTE_REQUEST после чего ожидает
прихода ответов. Если хотя бы один участник голосует за прерывание
транзакции, это становится итоговым решением и координатор рассылает
участникам сообщение GLOBAL_ABORT. Однако
если транзакция может быть подтверждена, рассылается сообщение PREPARE_COMMIT. Только
после того, как все участники подтвердят свою готовность к подтверждению,
координатор посылает итоговое сообщение GLOBAL_COMMIT, в результате которого транзакция
действительно подтверждается. И снова
существует лишь несколько ситуаций, в которых процесс блокируется и ожидает
сообщений. Во-первых, когда участник, находясь в состоянии INIT, ожидает прихода запроса на
голосование, он может в итоге перейти в состояние ABORT, что будет означать поломку координатора. Эта ситуация
идентична ситуации для протокола 2РС. Также аналогично координатор может
находиться в состоянии WAIT, ожидая
голосов участников. По истечении заданного времени координатор решает, что
участник отказал, и обрывает транзакцию путем рассылки сообщения GLOBAL_ABORT. Рассмотрим
теперь блокировку координатора в состоянии PRECOMMIT. В случае истечения заданного времени он приходит к
выводу, что один из участников отказал, но прочие участники знают, что они
голосовали за подтверждение транзакции. Соответственно, координатор
приказывает работающим участникам подтвердить транзакцию путем рассылки
сообщения GLOBAL_COMMIT. Кроме
того, он полагает, что протокол восстановления отказавшего участника поможет
подтвердить его часть транзакции после того, как этот участник будет
восстановлен. Участник
Р может блокироваться в состоянии READY или PRECOMMIT. После
окончания отведенного участнику Р на
ожидание времени, Р в
состоянии понять, что координатор отказал и нужно решать, что делать дальше.
Как и в 2РС, если Р при контакте с другим участником
обнаружит, что он находится в состоянии COMMIT (или ABORT), Р также переходит в это состояние. Кроме
того, если все участники находятся в состоянии PRECOMMIT, транзакция может быть без проблем подтверждена.
Опять-таки, аналогично схеме 2РС, если другой участник Q по-прежнему находится в состоянии
INIT, транзакция может быть
совершенно спокойно прервана. Важно отметить, что Q может находиться в состоянии INIT только в том случае, если ни один из участников не
находится в состоянии PRECOMMIT. Участник
может перейти в состояние PRECOMMIT,
только если координатор перед сбоем сам перешёл в состояние PRECOMMIT, а значит, получил голоса
всех участников. Другими
словами, участник не может оставаться в состоянии INIT, когда другой участник переходит в состояние PRECOMMIT. Если каждый из
участников, с которым может связаться Р, находится в состоянии READY
(и вместе они образуют большинство), транзакция должна быть прервана.
Здесь следует отметить, что если один из участников отказывает, позже он
будет восстановлен. Однако ни Р, ни любой
другой активный участник не знают, в каком состоянии будет находиться
отказавший участник после восстановления. Если процесс будет восстановлен в
состоянии INIT, решение о
прерывании транзакции - единственно верное. В наихудшем случае процесс может
восстановиться в состоянии PRECOMMIT,
но и в этом случае он не сможет помешать прерыванию транзакции. Этим
ситуация сильно отличается от протокола 2РС, где отказавший участник может
восстановиться в состоянии COMMIT, тогда
как все прочие участники будут находиться в состоянии READY. В этом случае оставшиеся рабочие процессы не смогут
принять итогового решения и вынуждены будут ожидать
восстановления отказавшего процесса. В ЗРС, если какой-то из рабочих процессов
находится в состоянии READY, отказавшие
процессы не смогут восстановиться ни в каком другом состоянии, кроме INIT, ABORT или PRECOMMIT. По этой причине
оставшиеся невредимыми процессы всегда смогут прийти к итоговому решению. И,
наконец, если процессы, такие как Р, могут достичь
состояния PRECOMMIT (и они
составляют большинство), то можно без проблем подтвердить транзакцию. И снова
мы можем видеть, что все остальные процессы либо находятся в состоянии READY, либо, как минимум, если они
отказали, будут восстановлены в состоянии READY, PRECOMMIT или COMMIT. 6. Работа RPC при наличии ошибок. Назначение RPC - скрыть сам факт
взаимодействия путем вызовов удаленных процедур, которые выглядят так же, как
локальные вызовы. Пока и клиент и сервер работают без ошибок, механизм RPC
отлично справляется со своим делом. Проблемы возникают, когда начинаются
ошибки. Причина проблем кроется в том, что при наличии ошибок скрыть разницу
между локальными и удаленными вызовами гораздо сложнее. Чтобы систематизировать
обсуждение, разделим ошибки, которые могут возникнуть в системах RPC, на пять
классов следующим образом: клиент
не в состоянии обнаружить сервер; потеря
сообщения с запросом от клиента к серверу; поломка
сервера после получения запроса; потеря
ответного сообщения от сервера к клиенту; поломка
клиента после получения ответа. Ошибки каждого из этих классов
ставят перед нами различные задачи, которые требуют различных способов
решения. 6.1. Клиент не в состоянии
обнаружить сервер. Начнем с того, что происходит,
если клиент не в состоянии обнаружить подходящий сервер, который может быть,
например, отключен. С другой стороны, клиент может быть скомпилирован с
некоей конкретной версией клиентской заглушки. Если исполняемый файл
длительное время не используется, за это время сервер может обзавестись новой
версией интерфейса, могут быть созданы и запущены новые заглушки. В этом
случае после запуска клиента может оказаться, что он не соответствует
серверу, вызывая сообщение об ошибке. Поскольку подобный механизм
используется для защиты клиента от попыток обмена с «неправильным» сервером
(сервером, с которым клиент не может договориться об используемых параметрах
или решаемых задачах), нужно определиться, что делать с такой ошибкой. Одно из возможных решений состоит
в том, чтобы заставить ошибку возбуждать исключение (exception). В некоторых
языках (например, в Java) программисты могут писать
специальные процедуры, которые вызываются в случае определенных ошибок,
например деления на ноль. Для этой цели можно использовать обработчики
сигналов. Другими словами, мы можем определить новый тип сигнала и
потребовать его обработки наравне с любыми другими сигналами. Этот подход, разумеется, имеет
свои минусы. Для начала, не все языки поддерживают такие конструкции, как
исключения или сигналы. Кроме того, написание процедуры обработки исключения
или сигнала нарушит прозрачность, которой мы так старались добиться. 6.2. Потеря сообщения с запросом. Второй элемент в нашем списке
касается потери сообщений с запросами. С этим справиться проще всего:
отправляя сообщение, операционная система или клиентская заглушка просто
должна включать таймер. Если таймер переполнится, а ответ или подтверждение
так и не будет получен, сообщение посылается повторно. Если сообщение действительно
пропало, сервер не увидит разницы между повторрюй
посылкой и оригиналом и все произойдет так, как нужно. Разумеется, если
пропадет такое количество сообщений, что клиент откажется от своей затеи и
ошибочно решит, что сервер не работает, мы снова вернемся к ситуации
«невозможно найти сервер». Если запрос не пропал окончательно, то нам следует
сделать так, чтобы сервер был в состоянии обнаружить, что имеет дело с
повторной посылкой. Следующая ошибка в списке -
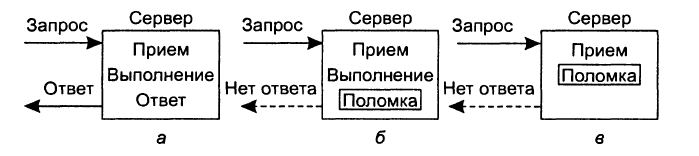
поломка сервера. Нормальную последовательность событий на сервере
иллюстрирует рис. 5а. Запрос
приходит, обрабатывается и посылается ответ. Рассмотрим теперь рис. 5б. Запрос приходит и
обрабатывается, как и в предыдущем случае, но на сервере происходит поломка
до того, как он успевает отправить ответное сообщение. И
наконец, посмотрим на рис. 5в. Снова приходит запрос, но на этот раз сервер
ломается еще до начала обработки.
Рис. 5.
Сервер при взаимодействии клиент-сервер. Нормальная работа (а). Поломка после
обработки запроса (б). Поломка до обработки запроса (в). Правильные действия в случаях (б) и (в) различны. В случае (б) система должна передать клиенту
сообщение об ошибке (например, возбудить исключение), в то время как в случае
(в) она может просто послать
запрос повторно. Проблема состоит в том, что
операционная система клиента не в состоянии понять, что именно произошло. Её
таймер переполнился - вот всё, что ей известно. Вопрос о том, что делать в
данном случае, разные школы решают по-разному. Одна из методик состоит в том, чтобы ожидать перезагрузки сервера (или
связаться с новым сервером) и повторить операцию. Идея - повторять попытки до
тех пор, пока сервер не выдаст ответ, который дойдет до клиента. Подобный
приём называется семантикой «минимум
однажды» (at least once semantics) и
гарантирует, что вызов RPC будет произведён как минимум один раз, а возможно
и больше. Другая методика состоит в том,
чтобы немедленно отказаться от дальнейших попыток и вернуть сообщение об
ошибке. Этот приём называется семантикой
«максимум однажды» (at most
once semantics) и
гарантирует, что вызов RPC будет произведён максимум один раз, а возможно и
ни разу. Третья из методик не гарантирует
ничего. Когда на сервере происходит поломка, клиент не получает никакой
помощи и никаких гарантий. Вызов RPC может быть не произведён ни разу или
произведён любое количество раз. Основное достоинство этой схемы - в простоте
её реализации. К сожалению, ни один из этих
подходов не предоставляет корректного механизма выхода из сложившейся
ситуации. Вариант решения мог бы быть предоставлен семантикой «только однажды» (exactly once semantics), но обычно её невозможно реализовать. Рассмотрим операцию удалённой
печати текста с посылкой сервером сообщения о завершении работы клиенту после
завершения печати. Также предположим, что в ответ на посылку запроса клиент
получает подтверждение доставки этого запроса на сервер. Сервер может
действовать двумя способами. Он может посылать клиенту сообщение об окончании
работы ещё до того, как на самом деле отправит задание на принтер, или после
того, как текст будет напечатан. Предположим, что сервер был
сломан, а затем восстановился. Он оповещает всех клиентов о том, что был
сломан, но теперь работает снова. Проблема в том, что клиенты не знают, были
или нет обработаны их запросы на печать текста.
Клиент может выбирать одну стратегию из четырех. Во-первых, клиент может никогда не
повторять запроса, невзирая на риск, что текст не будет напечатан. Во-вторых, он может всегда
повторять запрос, но это может привести к тому, что текст будет напечатан
дважды. В-третьих, клиент может решить
повторять запрос только в том случае, если он не получал подтверждения
доставки запроса на печать на сервер. В этом случае клиент считает, что
сервер сломался до получения запроса на печать. Четвёртая и последняя стратегия
состоит в том, чтобы повторить запрос только в случае получения подтверждения
о доставке запроса на печать. Имея две стратегии у сервера и
четыре у клиента, можно составить восемь комбинаций. К сожалению, ни одна из
них не может работать корректно. Чтобы объяснить, почему это так, рассмотрим
три события, которые должны происходить на сервере, - посылка сообщения о
завершении работы (ответ О), печать текста (печать П) и поломка
(неисправность Н). Эти события могут происходить в шести различных
последовательностях. О→П→Н: Поломка происходит после отсылки
сообщения и печати текста. О→Н(→П): Поломка происходит после отсылки
сообщения, но до печати текста. П→О→Н:
Поломка происходит
после отсылки сообщения и печати текста. П→Н(→О):
Печатается текст,
после чего происходит поломка (до отправки сообщения). Н(→П→О):
Поломка происходит до
того, как сервер успевает что-либо сделать. Н(→О→П):
Поломка происходит до
того, как сервер успевает что-либо сделать. Скобками отделены события, которые
не успевают произойти, поскольку сервер к этому времени уже сломан. Таблица 1
иллюстрирует все возможные комбинации. Как легко можно убедиться, не
существует такой комбинации стратегий клиента и сервера, которая
бы корректно работала при всех возможных последовательностях событий. И
последний штрих: клиент никогда не знает, сломался сервер до или после печати
текста. Таб. 1. Различные комбинации стратегий
клиента и сервера при наличии поломок на сервере
0 –
текст не печатается 1 –
текст печатается один раз 2 –
текст печатается дважды Говоря кратко, возможность поломки
сервера радикально изменяет природу RPC и проводит четкую грань между однопроцессорными
и распределёнными системами. В случае однопроцессорной системы поломка
сервера подразумевает поломку клиента, причём его восстановление при
неработающем сервере бессмысленно. В случае распределённой системы можно и
нужно предпринимать соответствующие действия. 6.4. Потеря ответного сообщения. С потерей ответных сообщений
справиться также нелегко. Очевидное решение - снова положиться на таймер,
установленный операционной системой клиента. Если за разумное время не было
получено ответа, можно просто послать запрос еще раз. Проблема этого решения
состоит в том, что клиент на самом деле не уверен в причине отсутствия
ответа. Потерялся запрос, потерялся ответ или просто сервер слишком
медленный? Между этими вариантами имеется существенная разница. Некоторые операции можно без
проблем повторять столько раз, сколько нужно, и это не вызовет никаких
нарушений. Так, например, запрос на чтение первых 1024 байт файла не имеет
побочных эффектов и может производиться так часто, как это необходимо без
каких-либо проблем. Теперь рассмотрим запрос к
банковскому серверу, требующий перевода миллиона долларов с одного счета на
другой. Если запрос пришел и был выполнен, но ответное сообщение потерялось,
клиент ничего не знает о выполнении запроса и посылает его повторно.
Банковский сервер считает, что это новый запрос, и выполняет его. Переводятся
два миллиона долларов. Вся надежда на то, что
ответное сообщение не потеряться 10
раз. Способ борьбы с возникающей
ситуацией состоит в том, что клиент присваивает каждому запросу
последовательный номер. Если заставить сервер сохранять
номер последнего принятого сообщения каждого из клиентов, работавших с этим
сервером, он сможет обнаружить разницу между оригинальным и повторным
запросами. Тогда сервер откажется выполнять запрос во второй раз, но
сможет повторно послать клиенту ответ. Отметим, что подобный подход требует,
чтобы сервер занимался отслеживанием всех клиентов. Дополнительной защитой
послужит специальный бит в заголовке сообщения, позволяющий отличать исходные
запросы от повторных передач (мы предполагаем, что выполнение исходного
запроса всегда безопасно, тогда как его повторение требует осторожности). Последний пункт
в списке ошибок - поломка клиента. Что произойдет, если клиент пошлёт
серверу запрос на некие действия и сломается, прежде чем сервер ответит ему?
В этом случае вычисления будут произведены, но у нас не окажется заказчика,
ожидающего результата. Такие не имеющие заказчика вычисления называются сиротами (orphans). Сироты могут породить
разнообразные проблемы. Как минимум, они вызовут излишнюю трату процессорного
времени. Они могут также блокировать файлы или как-то иначе связывать
полезные ресурсы. И наконец, если клиент
перезагрузится и вновь выполнит вызов RPC, а сразу после этого к нему придет
ответ от процесса-сироты, может возникнуть хаос. Что делать с сиротами?
Предлагаются четыре решения. В соответствии с решением 1, перед тем как
клиентская заглушка пошлет вызов RPC, она создает запись в журнале с
описанием того, что происходит. Журнал хранится на диске или другом
устройстве долговременного хранения информации, способном пережить
перезагрузку. После перезагрузки клиента журналы проверяются и все сироты
уничтожаются. Это решение называется истреблением
сирот (extermination). Недостатки этого сценария в том,
что он требует для каждого вызова RPC записи на диск огромного объема
информации. Однако он может и не сработать, если сироты сами по себе способны
делать вызовы RPC, создавая внучатых
сирот (grandorphans) или сирот еще большей
степени, которых трудно или вообще невозможно обнаружить. И, наконец, сеть
может быть разделена на фрагменты, например, сломавшимся шлюзом, что сделает
невозможным истребление сирот, даже если их удастся найти. Все показывает,
что это не слишком многообещающий подход. Согласно решению 2, именуемому реинкарнацией
(reincarnation), все эти проблемы могут быть
решены без записи на диск. Способ, которым это делается, предполагает
разбиение времени на последовательно пронумерованные эпохи. При перезагрузке клиента он путем
широковещательной рассылки отправляет всем машинам сообщение, объявляющее о
начале новой эпохи. Когда эта рассылка приходит на сервер, все удаленные
вычисления, производимые там по заказу этого клиента, прекращаются.
Разумеется, если сеть разделена на части, некоторые сироты могут выжить.
Однако в ответах от них будет содержаться номер прошедшей эпохи, что предельно
упростит их обнаружение. Решение 3 - это вариант предыдущей
версии, но не настолько драконовский. Он называется мягкой реинкарнацией (gentle
reincarnation). Когда приходит сообщение о смене эпох, каждая машина
проверяет, происходят ли на ней какие-либо удаленные вычисления, и если да,
пытается найти их владельца. Вычисления прекращаются только в том случае,
если владельца найти не удалось. И, наконец, у нас есть решение 4 -
истечение срока (expiration).
В этом решении каждому вызову RPC приписывается стандартная
продолжительность работы. Если
он не закончил работу, то должен явным образом затребовать следующий срок,
что создает определенные неудобства. С другой стороны, если после поломки
клиента до его перезагрузки проходит время T, все сироты точно успевают
умереть. Проблема решается путем выбора разумного времени T для вызовов RPC с сильно различающимися
требованиями. 7. Надежная групповая рассылка.
Базовые схемы надежной групповой рассылки. Надёжные службы групповой рассылки
имеют большое значение. Подобные службы гарантируют, что сообщения будут
доставлены всем процессам в группе. К сожалению, реализовать надежную
групповую рассылку не просто. Хотя большинство систем
транспортного уровня предоставляют в наше распоряжение надежные сквозные
каналы, средства для надежного взаимодействия с набором процессов встречаются
значительно реже. Самое лучшее, что системы транспортного уровня в состоянии
сделать, это позволить любому процессу создать сквозное соединение с любым
другим процессом, с которым ему необходимо связаться. Очевидно, что подобная
организация связи не слишком эффективна, поскольку она требует слишком
большого расхода пропускной способности сети. Однако, если число процессов
мало, надежная групповая рассылка через несколько надежных сквозных каналов представляет собой самое простое
решение, которое часто используется на практике. Следует точно определить, что
такое надёжная групповая рассылка (reliable multicasting). Сообщение,
отправленное группе процессов, должно быть гарантированно доставлено всем
членам этой группы. Однако что произойдет, если процесс станет членом группы
непосредственно в момент рассылки? Должен ли этот процесс также получить
сообщение? Точно так же мы должны определить, что произойдет, если
отправляющий сообщение объект в процессе
взаимодействия откажет. Чтобы разрешить и эти ситуации,
следует провести границу между надежной связью в присутствии ошибочно
функционирующих процессов и надежной связью с корректно работающими процессами.
В первом случае групповая рассылка считается надёжной, если можно
гарантировать получение сообщения всеми правильно работающими членами группы.
Сложность в том, что вдобавок ко всем ограничениям, связанным с организацией
процессов в группе, необходимо выяснить, какие процессы входили в группу до
получения сообщения. Ситуация немного прояснится, если
допустить, что существует соглашение о том, кто является членом группы. Так,
в частности, если предположить, что процессы в ходе сеанса связи не
отказывают, не входят в группу и не покидают ее, то надёжная групповая
рассылка будет просто означать, что любое сообщение доставляется всем текущим
членам группы. В простейшем случае между членами группы нет договоренности о
доставке сообщений всем членам группы в определенном порядке, но иногда
подобное условие необходимо. Подобная наиболее слабая форма надежной
групповой рассылки, относительно просто реализуемая, применяется в том случае,
если число приемников мало. Рассмотрим случай, когда один
передатчик должен сделать групповую рассылку для нескольких приемников.
Предположим, что базовая система связи обеспечивает только ненадежную
групповую рассылку, то есть групповые сообщения могут быть частично потеряны,
а частично доставлены, но не всем потенциальным потребителям. Простой способ реализации надежной
групповой рассылки в таких условиях выглядит следующим образом: передающий
процесс приписывает каждому рассылаемому сообщению последовательный номер.
Предположим, что сообщения принимаются в том же порядке, в котором
рассылаются. В этом случае получатель с легкостью обнаружит пропажу
сообщения. Каждое посылаемое сообщение сохраняется отправителем в локальном
буфере истории. Полагая, что получатели знают, кто отправлял сообщение,
отправитель просто сохраняет сообщение в буфере до получения подтверждения
его приёма ото всех получателей. Если получатель обнаружит пропажу сообщения,
он возвращает отправителю отрицательное подтверждение, запрашивая повторную
передачу. С другой стороны, отправитель, не получивший подтверждения в
течение заданного срока, может произвести повторную передачу автоматически. При разработке могут быть
использованы различные хитрости. Так, например, чтобы сократить число возвращаемых
отправителю сообщений, подтверждения могут вкладываться в другие сообщения.
Кроме того, повторная передача может производиться как по сквозному каналу с
каждым из затребовавших её процессов, так и путем групповой рассылки одного
сообщения всем процессам. Основная проблема описанной выше
схемы групповой рассылки состоит в том, что она не в состоянии работать с
большим количеством получателей. При наличии N получателей отправитель должен
быть готов обрабатывать как минимум N
подтверждений. Если получателей будет много, отправитель может быть
просто погребён под ответами. Этот эффект известен под названием обратный удар (feedback
implosion). Кроме того, мы должны принимать
во внимание и тот факт, что получатели могут быть разбросаны по всей
глобальной сети. Одно из решений проблемы состоит в
том, чтобы запретить получателям подтверждать приём
сообщения. Вместо этого получатель должен посылать сообщение отправителю
только при потере сообщения. Если возвращать только негативные подтверждения,
серьезность проблем с масштабированием будет значительно снижена, но твёрдые
гарантии того, что обратный удар никогда не произойдёт, по-прежнему
отсутствуют. Другая проблема с получением
только негативных подтверждений состоит в том, что отправитель теоретически
может быть вынужден вечно хранить сообщения в буфере истории. Поскольку
отправитель не в состоянии узнать, было ли сообщение доставлено всем
получателям, он должен всегда быть готов к тому, что один из получателей
потребует повторно послать ему какое-нибудь древнее сообщение. Практически
отправитель должен удалять сообщения из своего буфера истории по истечении
определенного срока, что предохранит буфер от переполнения. Однако удаление
сообщения всегда чревато тем, что один из запросов на повторную передачу не
будет удовлетворен. Существуют два диаметрально
противоположных подхода к реализации групповых рассылок. 7.1.
Неиерархическое управление обратной связью. Ключевая задача при создании масштабируемых
решений для надёжной групповой рассылки - уменьшение числа откликов,
получаемых отправителем от получателей. В некоторых глобальных приложениях
используется популярная модель подавления
откликов (feedback suppression),
которая лежит в основе протокола масштабируемой надежной групповой
рассылки (Scalable Reliable Multicasting, SRM), работающего следующим
образом. Прежде всего, в SRM получатель
никогда не подтверждает успешного приёма сообщения, посылая отклик только в
случае потери сообщения. Как приложение отслеживает потерю сообщения, зависит
от него самого. Итак, в качестве отклика возвращаются только негативные
подтверждения. Когда получатель обнаруживает, что он потерял сообщение, он,
пользуясь групповой рассылкой, посылает свой отклик остальным членам группы. Посланный путем групповой рассылки
отклик заставляет других членов группы отказаться от посылки своих
собственных сообщений. Допустим, что сообщение не дошло до нескольких членов группы. Каждый из них должен
послать отправителю негативное подтверждение, чтобы тот повторно послал
сообщение. Однако если, как
мы говорили, повторная посылка всегда выполняется средствами групповой
рассылки, понятно, что для повторной посылки будет вполне достаточно, если
отправитель получит
один-единственный запрос. По этой причине получатель, не получивший сообщения,
планирует посылку отклика с некоторой случайной задержкой. То есть запрос на
повторную посылку отправляется только по прошествии некоторого случайного
интервала времени. Если, однако, в это время к получателю приходит другой запрос на
повторную посылку, он отменит
посылку собственного отклика, зная, что сообщение скоро и так будет послано
повторно. Таким образом, в идеале до отправителя дойдёт только одно сообщение, которое, в свою очередь, вызовет
повторную посылку исходного сообщения. Подавление отклика приводит к
значительному повышению масштабируемости и
используется в качестве базового механизма для множества кооперативных Интернет-приложений, таких как совместно используемые
доски объявлений. Однако, такой подход порождает
множество серьёзных проблем. Во-первых, чтобы гарантировать, что отправитель
получит только один запрос на повторную посылку, необходимо очень точно
планировать отклик каждого из получателей. В противном случае множество получателей
могут послать свои отклики одновременно. Установка таймеров в разбросанных по
глобальной сети группах процессов - задача непростая. Другая проблема состоит в том, что
групповая рассылка отклика прерывает работу и тех процессов, которые успешно
получили сообщения. Другими словами, получатели вынуждены принимать и
обрабатывать ненужное им сообщение. Единственное решение этой проблемы -
выделить получателей, оставшихся без сообщения в отдельную группу для
групповой рассылки. К сожалению, это решение требует очень эффективного
управления группами, что в глобальных системах трудноосуществимо. Наилучшим
подходом поэтому было бы объединить получателей, имеющих тенденцию к пропуску
одинаковых сообщений, в группу и использовать один и тот же канал групповой рассылки как для откликов, так и для повторной посылки
сообщений. Для повышения масштабируемости
SRM можно потребовать, чтобы получатели осуществляли локальное
восстановление. Так, если получатель, который успешно получил сообщение,
получает затем запрос на повторную посылку, он сам еще до того, как запрос
дойдет до истинного отправителя, может решить разослать это сообщение. 7.2. Иерархическое управление
обратной связью. Описанный выше механизм подавления
откликов в основе своей не является иерархическим. Однако,
чтобы добиться масштабируемости в очень больших
группах получателей, необходимо применить иерархический подход. Для простоты будем считать, что рассылкой
сообщений большой группе получателей занимается только один отправитель.
Группа получателей разбита на множество подгрупп, которые организованы в виде
дерева. Подгруппа, содержащая отправителя, образует корень дерева. Внутри
каждой из подгрупп может использоваться любая схема групповой рассылки,
подходящая для малой группы. В каждой подгруппе определяется
локальный координатор, который отвечает за обработку запросов на повторную
передачу, отправляемых получателями, входящими в эту подгруппу. Локальный
координатор поддерживает для этой цели собственный буфер истории. Если сам
координатор пропускает сообщение, он запрашивает повторную рассылку этого
сообщения у координатора родительской подгруппы. В схеме с подтверждениями
локальный координатор, приняв сообщение, посылает подтверждение своему
родителю. Если координатор получил подтверждения приёма сообщения от всех членов своей подгруппы, а
также от всех их потомков, он может удалить это сообщение из своего буфера
истории. Основная проблема в иерархическом
подходе - построение дерева. Во многих случаях дерево должно строиться
динамически. Один из способов сделать это - использовать дерево групповой
рассылки базовой сети, если оно существует. В принципе для этого достаточно
расширить задачу маршрутизаторов групповой рассылки
сетевого уровня таким образом, чтобы они могли выполнять функции локальных
координаторов. К сожалению, адаптировать таким
образом существующую компьютерную сеть не так-то легко. Мы можем заключить,
что построение надежных схем групповой рассылки, которые можно было бы
масштабировать на варианты систем с большим числом получателей,
распределенных по глобальной сети, представляет собой сложную проблему. Не
существует какого-либо наилучшего решения, а каждое из существующих
порождает новые проблемы. 8. Распределённая система Jini. Не смотря на то, что
рассматриваемая далее распределённая система Jini базируется на принципах модели взаимодействия удаленного обращения
к методам RMI, описание которого в данной статье не приводится, интересен
именно принцип работы системы в целом без привязки к модели взаимодействия.
Именно по этой причине рассмотрение данной системы является целесообразным. Jini - это распределённая система,
состоящая из разных, но взаимосвязанных элементов. Она жёстко привязана к
языку программирования Java, хотя многие из её
принципов равно могут быть реализованы и при помощи других языков. Важной частью системы является
модель согласования генеративной связи. Jini обеспечивает как временную, так и
ссылочную несвязность процессов при помощи системы согласования JavaSpace.
JavaSpace - это разделяемое пространство данных, в котором
хранятся кортежи. Кортежи представляют собой типизованные наборы ссылок на
объекты Java. В одной системе Jini
могут сосуществовать несколько пространств JavaSpace. Кортежи хранятся в сериализованной форме. Другими словами, когда бы процессу
ни потребовалось сохранить кортёж, сначала выполняется маршалинг
кортежа, причём также подразумевается маршалинг
всех его полей. В результате если кортёж содержит два разных поля,
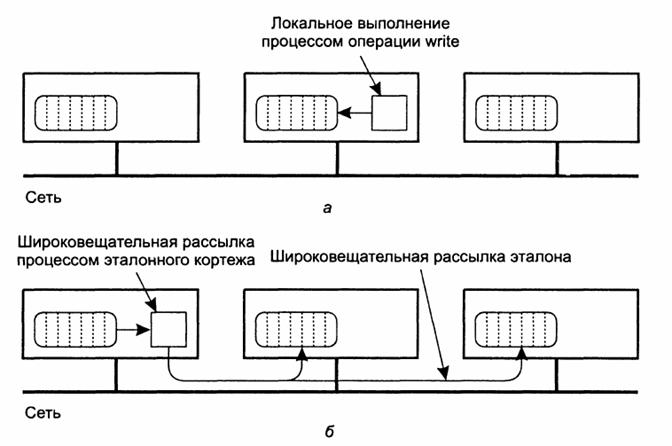
ссылающихся на один и тот же объект, то кортёж, сохраняемый в реализации JavaSpace, будет содержать две подвергнутые маршалингу копии этого объекта. Кортёж помещается в пространство JavaSpace при помощи операции write,
которая сначала выполняет маршалинг кортежа, а
затем сохраняет его. Каждый раз при выполнении для кортежа операции write в JavaSpace сохраняется
новая подвергнутая маршалингу копия этого кортежа.
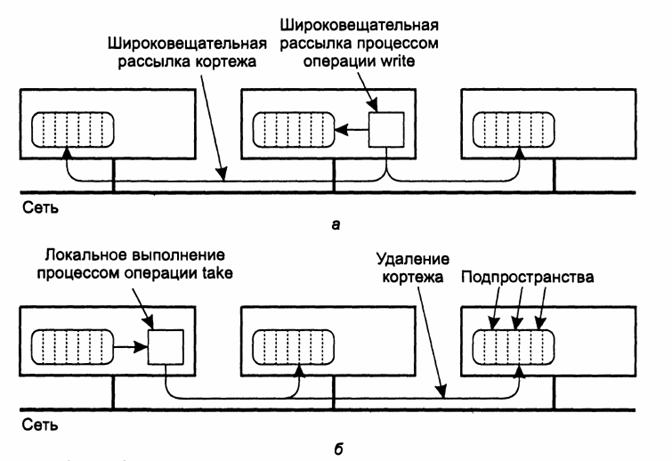
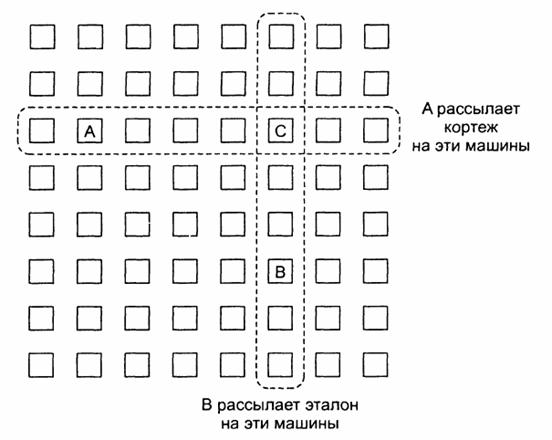
Мы можем ссылаться на каждую такую копию, как на экземпляр кортежа (tuple instance). Интересный аспект генеративной связи в Jini - это способ чтения экземпляров кортежа в JavaSpace. Чтобы прочесть экземпляр кортежа, процесс
предоставляет другой кортёж и использует его как эталон (template), соответствующий
считываемым экземплярам кортежа, хранящимся в JavaSpace.
Как и любой другой кортёж, эталонный кортёж представляет собой типизованный
набор ссылок на объекты. В JavaSpace можно
прочитать только экземпляры тех кортежей, которые имеют одинаковый с эталоном
тип. Поля в эталонном кортеже также содержат либо ссылки на реальные объекты,
либо значение NULL. Чтобы сопоставить экземпляр кортежа
в JavaSpace эталонному кортежу, обычным образом
выполняется маршалинг эталонного кортежа, включая маршалинг полей со значением NULL. Для каждого экземпляра
кортежа того же типа, что и эталон, производится сравнение, поле за полем, с
подвергнутыми маршалингу полями эталонного кортежа.
Два поля совпадают, если оба они содержат копии одной и той же ссылки или
если поле в эталонном кортеже равно NULL. Экземпляр кортежа совпадает с
эталонным кортежем, если попарно совпадают соответствующие поля. Когда обнаруживается экземпляр
кортежа, совпадающий с эталонным кортежем (который является частью операции read), выполняется демаршалинг
этого экземпляра, и он возвращается процессу, инициировавшему чтение. Для
чтения может быть использована также операция take,
которая заодно удаляет экземпляр кортежа из пространства JavaSpace.
Обе операции блокируют вызвавший их процесс до обнаружения нужного экземпляра
кортежа. Максимальное время блокирования можно предсказать. Кроме того,
существуют реализации, немедленно возвращающие управление, если нужного
кортежа не существует. JavaSpace образует лишь одну из частей
системы Jini. Jini
существует в виде компактного набора полезных средств и служб, на базе которых
можно разрабатывать распределённые приложения. Распределённое приложение на
базе Jini часто представляет собой свободное
сообщество устройств, процессов и служб. Всё взаимодействие в существующих
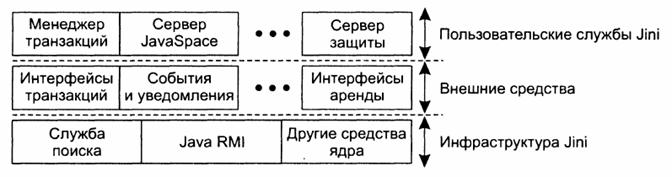
системах Jini построено на обращениях RMI языка Java. Архитектура системы Jini может быть представлена в виде трех уровней, как это
показано на рис. 6. Самый нижний уровень образует инфраструктура. На этом
уровне располагаются базовые механизмы Jini, в том
числе и те, которые поддерживают взаимодействие посредством обращений RMI
языка Java. Следует отдельно отметить одно важное
свойство модели Jini: клиенты легко могут найти
нужную им службу. Службы предоставляются как обычными процессами, так и
устройствами, на которых программное обеспечение Jini,
в том числе и виртуальная машина Java, выполняться
не может. Поэтому регистрирующие и поисковые службы также относятся к
инфраструктуре Jini.
Рис.
6. Многоуровневая архитектура системы Jini Второй уровень образуют средства
общего назначения, которые дополняют базовую инфраструктуру и могут быть
использованы для более эффективной реализации служб. В число этих средств в
настоящее время входят подсистемы событий и уведомлений, средства аренды
ресурсов и описания стандартных интерфейсов транзакций. Самый верхний уровень состоит из
клиентов и служб. В противоположность остальным двум уровням Jini не определяет состав этого уровня однозначным
образом. В настоящее время система поддерживает несколько служб верхнего
уровня, среди которых сервер JavaSpace и менеджер
транзакций, реализующий интерфейсы транзакций Jini.
Программам верхнего уровня, кроме того, нередко разрешается напрямую
использовать механизмы инфраструктуры Jini. Кроме генеративной связи, присущей
модели JavaSpace, в число механизмов взаимодействия
Jini входит простая подсистема событий и
уведомлений. Модель событий Jini
относительно проста. Если в рамках объекта происходит событие, которое может быть
интересно клиенту, клиенту разрешается зарегистрировать себя на этом объекте.
Когда факт наступления события будет зафиксирован, то есть когда событие
произойдет, объект уведомит об этом зарегистрированного клиента. С другой
стороны, клиент может потребовать от объекта, чтобы тот послал уведомление о
наступлении события в другой процесс. В этом случае объекту пересылается
удаленная ссылка на объект-слушатель (listener object), обратный вызов которого можно выполнить
при наступлении события. Регистрация всегда арендуется.
Когда срок аренды истекает, зарегистрированный клиент (или процесс, которому
уведомления отправлялись по поручению клиента) перестает получать
уведомления. Благодаря аренде регистрация не может сохраниться вечно,
например, в результате отказа зарегистрированного клиента. Уведомление о событии реализуется
объектом путем удаленного вызова объекта-слушателя, зарегистрированного для
этого события. При следующем наступлении события объект-слушатель вызывается
снова. Поскольку система Jini сама по себе не
предоставляет никаких гарантий того, что уведомление о событии будет
доставлено объекту-слушателю, уведомления обычно имеют порядковые номера,
чтобы объект-слушатель имел представление об очередности событий. События также могут использоваться
и в JavaSpace. Так, в частности, клиент может
попросить уведомлять его о том, что в JavaSpace
записан определённый экземпляр кортежа. Для этого клиент вызывает операцию notify, реализованную во всех пространствах JavaSpace. Эта операция получает в качестве исходных
данных эталонный кортёж, который сличается с экземплярами кортежей,
хранящимися в JavaSpace, точно так же, как это
происходит в ходе операций read или take. Реализация сервера JavaSpace требует особого внимания. Рассмотрим наиболее
общий случай, когда набор экземпляров кортежей может быть разбросан по
нескольким машинам. Эффективная распределенная реализация JavaSpace
должна решать два вопроса: как
эмулировать ассоциативную адресацию без глобального поиска; как
распределить экземпляры кортежей по машинам и как их
потом обнаружить. Ключ к решению данных вопросов
состоит в том, чтобы считать каждый кортёж структурой данных определенного
типа. Разделив пространство кортежей на подпространства, в каждом из которых
находятся кортежи одного типа, мы упрощаем программирование и делаем
возможной некоторую оптимизацию. Так, например, поскольку кортежи
типизированы, то уже на этапе компиляции можно определить, в каком
подпространстве производится данная операция write,
read или take. Такое
дробление означает, что поиск экземпляра кортежа будет производиться не во
всем наборе кортежей, а только в его части. Кроме того, каждое из этих
подпространств можно организовать в виде хэш-таблицы, использующей поле записи или его часть в
качестве ключа хэш-таблицы. Напомним, что каждое поле
экземпляра кортежа - это подвергнутая маршалингу
ссылка на объект. Jini не определяет способ маршалинга, поэтому маршалинг
ссылок в конкретной реализации может выполняться так, чтобы первые несколько
байтов ссылки после маршалинга определяли тип
объекта, на который она указывает. Таким образом, вызов операций write, read или take может осуществляться путем вычисления значения
хэш-функции i-ro поля, в результате чего мы получим
положение экземпляра кортежа в таблице. Зная подпространство и положение
экземпляра кортежа в таблице, можно ничего не искать. Разумеется, если z-e поле при операции read или take равно NULL, хэширование
невозможно и придётся провести полный поиск в подпространстве. Однако, если аккуратно выбрать поля для хэширования,
то обычно такого поиска можно избежать. Используется также и
дополнительная оптимизация. Например, схема хэширования,
описанная выше, распределяет кортежи в заданных подпространствах по контейнерам,
чтобы ограничить поиск одним контейнером. Можно разместить разные контейнеры
на различных машинах, чтобы более разумно распределить загрузку и
воспользоваться преимуществами локальных операций. Если функцией хэширования является модуль числа машин, число
контейнеров будет расти в линейной зависимости от размера системы. Кратко рассмотрим различные
способы реализации описанной схемы на машинах разных типов. В
мультипроцессоре подпространства кортежей можно реализовать в виде хэш-таблиц
в глобальной памяти, по одной на каждое подпространство. При осуществлении
операции JavaSpace соответствующее подпространство
блокируется, к нему добавляется или удаляется экземпляр кортежа, после чего
подпространство разблокируется. В мультикомпьютере
наилучший выбор зависит от коммуникационной системы. Если в нашем
распоряжении имеется надёжная широковещательная рассылка, можно всерьез
рассматривать идею о полной репликации всех подпространств на всех машинах,
как показано на рис. 7. При осуществлении записи (write)
новый экземпляр кортежа рассылается по всем машинам и добавляется на каждой
из них в соответствующее подпространство. Поиск при выполнении операции read или take производится в
локальном подпространстве. Однако успешное выполнение операции take требует удаления экземпляра кортежа из JavaSpace, а для того, чтобы удалить этот экземпляр со
всех машин, требуется протокол удаления экземпляров кортежей. Чтобы
предотвратить условия гонок и взаимные блокировки (тупики), используется
протокол двухфазного подтверждения.
Рис. 7. Пространство JavaSpace можно распределить между машинами (дробление JavaSpace на подпространства показано пунктирными
линиями). Рассылка кортежей при выполнении операции write
(а). Операции read локальны, но удаление экземпляров
при выполнении операции take также должно
распространяться на все машины (б). Эта структура проста, но при её
масштабировании (если система будет наращивать число экземпляров кортежей и
размеры сети) могут возникнуть проблемы. Так, например, реализация этой схемы
в глобальной сети будет стоить безумно дорого. Другой вариант состоит в том,
чтобы производить операцию write локально, сохраняя
экземпляр кортежа только на той машине, на которой он был создан, как
показано на рис. 8. Для выполнения операции read
или take требуется широковещательная рассылка
эталонного кортежа. Каждая машина, получившая его, проверяет, хранится ли на
ней подобный кортеж, и, если да, отправляет соответствующий отклик. Если экземпляр кортежа отсутствует
или широковещательная рассылка не дошла до машины с нужным кортежем, то
машина, пославшая запрос, продолжает повторять рассылку, увеличивая интервалы
между сообщениями до тех пор, пока соответствующий экземпляр кортежа не
материализуется и запрос не будет удовлетворен. Если запрос приводит к
передаче двух или более экземпляров кортежа, соответствующих эталону, они
трактуются как локальные операции write.
Рис. 8. Не реплицированное пространство JavaSpace. Операция write
выполнятся локально (а). Операции read и take требуют широковещательной рассылки эталона для
поиска экземпляра кортежа (б). В результате эти экземпляры
перемещаются с машины, на которой они находились, на машину, которая посылала
запрос. На практике исполняющая система может перемещать кортежи с машины на
машину даже с целью балансирования загрузки. Описанные два метода можно
объединить, получив в результате систему с частичной репликацией. В качестве
простого примера представим себе, что все машины логически выстроены в
прямоугольную решетку, как показано на рис. 9. Когда процесс с машины А хочет
выполнить операцию write, он производит
широковещательную рассылку кортежа или рассылает его сквозными сообщениями
всем машинам в своей строке решетки. Когда процесс с машины
В хочет выполнить операцию read или take для экземпляра
кортежа, он производит широковещательную рассылку эталонного кортежа на все
машины в своем столбце. Вследствие такой геометрии всегда
найдется хотя бы одна машина (в нашем примере - С), имеющая и экземпляр кортежа,
и эталонный кортеж, и эта машина обнаружит соответствие и пошлёт экземпляр
кортежа запросившему его процессу.
Рис.
9. Частичная рассылка обычных и эталонных кортежей Данные реализации имеют серьёзные
проблемы масштабируемости. Их причина в том, что и
для вставки кортежа в пространство кортежей, и для его извлечения оттуда
требуется широковещательная рассылка. Глобальных реализаций пространства
кортежей не существует. В лучшем случае можно создать в одной системе
несколько пространств кортежей так, что каждое пространство кортежей можно
будет реализовать в виде одного сервера или локальной сети. В Jini
отсутствует служба именования в традиционном понимании этого термина, такая,
например, как в распределенных системах объектов или в распределенных
файловых системах. Подобную службу именования можно легко реализовать в
архитектуре Jini в виде приложения верхнего уровня,
но в ядро Jini она не входит. Тем не менее в состав Jini входит служба,
которая позволяет клиентам находить зарегистрированные службы верхнего
уровня, используя средства поиска по атрибутам. Одной из целей создания Jini была разработка системы, которая позволяла бы
клиентам с легкостью обнаруживать новые службы по мере их подключения. В принципе JavaSpace
в состоянии реализовать такую службу. Всякий раз при подключении службы к
существующей системе она добавляет в JavaSpace
описывающий её экземпляр кортежа. Клиенты, которые ищут определённую службу,
просят, чтобы пространство JavaSpace уведомляло их
при добавлении службы, соответствующей заявленным требованиям. Не полагаясь на JavaSpace, Jini имеет
собственную специализированную службу
поиска (lookup service), являющуюся
частью инфраструктуры нижнего уровня (см. рис. 6). Все службы верхнего уровня
должны зарегистрироваться в ней, отослав службе поиска
набор пар (атрибут-значение), которые
описывают, например, какие услуги предоставляет служба и как с ней можно
связаться. Клиент может найти службу, предоставив службе поиска эталон,
схожий с эталонным кортежем JavaSpace. Служба
поиска возвращает информацию о подходящих под эталон службах. Каждая служба имеет связанный с
ней идентификатор службы {service identifier), который
представляет собой глобальное уникальное 128-битное значение, генерируемое
службой поиска.
Служба использует этот идентификатор для регистрации элемента службы (service item) в службе поиска. Элемент службы представляет
собой запись с тремя полями, перечисленными в табл.
2. Таблица
2. Структура элемента службы
Поле ServicelD содержит идентификатор службы,
присвоенный этой службе службой поиска. Идентификатор используется как уникальный
ключ для службы поиска. Не может существовать двух элементов службы, которым
служба поиска выдала бы одинаковые идентификаторы. Поле Service содержит ссылку на объект. Во
многих случаях это ссылка на удалённый объект, а значит, клиент, получивший
при помощи службы поиска указанную ссылку, может немедленно обратится к этому объекту. Поле AttributeSets представляет собой набор кортежей,
схожих с кортежами JavaSpace. Каждый кортеж, в
сущности, соответствует объекту Java, а каждое поле
кортежа описывает пару (атрибут,
значение) этого объекта. Используя те же методы, что и в JavaSpace, клиент может выполнять поиск определенного
экземпляра кортежа с помощью эталонного кортежа. Служба поиска выберет только
те кортежи, которые соответствуют эталону. Как и в случае с JavaSpace, клиент может потребовать от службы поиска
уведомлять его о случаях добавления элементов службы, соответствующих
эталонному кортежу клиента. Каким же образом производится
поиск самой службы поиска? Стандартно применяемый во многих распределенных
системах способ состоит в том, чтобы сконфигурировать поисковый сервер на
общеизвестный адрес. В Jini используется другой
подход. Клиенту предлагается для локализации службы поиска произвести
групповую рассылку сообщения с запросом к этой службе. Если не принимать
специальных мер, этот подход эффективен только для локальных сетей. Кроме того, служба поиска и сама
регулярно объявляет о своём местоположении также путём групповой рассылки.
Клиент может определить местоположение службы поиска, а потом, когда ему
понадобится найти определенную службу, воспользоваться этими сведениями. С вопросами именования связаны
вопросы управления ссылками на объекты. Управление ссылками состоит в том, что
объекты отслеживают, кто на них ссылается, что приводит нас к так называемым
спискам ссылок. Чтобы удерживать размеры этих
списков в разумных пределах, а также иметь возможность обрабатывать случаи отказов
ссылающихся на объект процессов, удобно использовать аренду. По истечении
срока аренды ссылки становятся недействительными и удаляются из списка
ссылок. Когда список на объект становится пустым, объект может без опасений
самоуничтожиться. В системе Jini
аренда активно используется для удаления объектов, на которые никто не
ссылается. Так, например, когда процесс записывает кортеж в Java-Space, он получает аренду, определяющую, как долго
будет храниться этот кортеж и когда он должен быть уничтожен. В этом случае
операция записи позволяет объекту, который ее осуществляет, указать желаемое
время аренды. Аренда никогда не даёт полной
гарантии. Когда процесс устанавливает аренду, он действительно обещает
сделать всё возможное для сохранения арендованного объекта в течение как
минимум определённого времени. Процесс, которому предоставлена аренда, всегда
может попросить о её продлении. Однако арендодатель вправе решать,
согласиться на продление аренды или нет. Интерфейсы аренды стандартизованы.
При использовании аренды в Jini всюду соблюдаются
одни и те же спецификации. Jini поддерживает несколько механизмов
синхронизации. Один из важных классов подобных механизмов, а именно
блокирующие операции read и take,
реализован как часть JavaSpace. Эти операции
позволяют реализовать множество различных шаблонов синхронизации. Помимо
синхронизации посредством этих двух операций Jini
поддерживает также понятие транзакций. Чтобы способствовать выполнению
последовательностей операций над несколькими объектами, Jini
поддерживает транзакции, использующие протокол двухфазного подтверждения. Эта
поддержка, в сущности, сводится к предоставлению набора интерфейсов,
реализация оставлена другим. Однако Jini можно
сконфигурировать для работы со стандартным менеджером транзакций. Такой подход имеет важную
особенность. Дело в том, что свойства транзакции самой системой Jini не обеспечиваются. Взамен предполагается, что эти
свойства совместно реализуются процессами, принимающими участие в транзакции.
Однако взаимодействие между процессами соответствует шаблону транзакций с
двухфазным подтверждением. Общую модель транзакций в Jini
иллюстрирует рис. 10. Клиент может начать транзакцию,
послав запрос менеджеру транзакций, который вернёт идентификатор транзакции.
Как и во многих других случаях, клиент должен определить, сколько времени
может пройти до подтверждения или прерывания транзакции. Кроме того, менеджер
может назначить только что созданной транзакции аренду и прервать транзакцию
по истечении срока аренды независимо от состояния транзакции.
Рис. 10. Общая организация
транзакций в Jini. Толстые линии обозначают взаимодействие,
выполняемое в соответствии с требованиями протокола транзакций Jini. Клиент может требовать от других
процессов, чтобы они присоединились к транзакции. Такие процессы должны
реализовывать предопределённый интерфейс, который позволит менеджеру
транзакций управлять транзакцией. Этот интерфейс, содержащий такие операции,
как commit и abort,
вызывается менеджером транзакции, чтобы указать участнику транзакции, что ему
делать. Задача участника - корректно
реализовать эти методы. Если транзакция заканчивается до истечения срока
аренды, клиент указывает менеджеру транзакций, что он должен подтвердить или
прервать транзакцию. После этого менеджер транзакций
запускает протокол двухфазного подтверждения и сообщает о результатах
клиенту. Jini поддерживает также и вложенные
транзакции. В этом случае менеджеру транзакций посылается запрос с
требованием начать вложенную транзакцию в ходе существующей транзакции. И
снова клиент контролирует организацию транзакции, то есть определяет, какие
процессы примут в ней участие. При вложенной транзакции процессы должны
участвовать в конкретных частях общей транзакции. Пространство JavaSpace
также может участвовать в транзакциях. В транзакции могут принимать участие несколько
пространств JavaSpace. Когда процесс пересылает
пространству JavaSpace сведения об операции,
которую оно должно выполнить, процесс может передать также и идентификатор
транзакции. Главная / Принципы
построения распределённых вычислительных
сетей |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||