|
E=mс2bedded
Pro |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Контакты: E-mail: embedded_pro@mail.ru AppNotes: Сотовая связь Отправка коротких SMS в
формате PDU Отправка длинных SMS в формате PDU Получение и
декодирование SMS Распределённые
вычислительные сети Обзор распределённых
вычислительных сетей Принципы построения распределённых вычислительных
сетей Встраиваемые решения Обзор
встраиваемых операционных
систем Обзор
микропроцессоров ARM
Cortex-A BSP QNX Neutrino
для платы phyFLEX-iMX6 от PHYTEC |
Главная / Получение и
декодирование SMS Получение и декодирование SMS 5 марта Работа
с модемом
Приём SMS начинается
с GSM-модема. Модем управляется AT-командами. Рассмотрим кратко алгоритм
получения SMS от
модема. Режим PDU Рекомендую перевести
модем в PDU-режим перед всеми операциями командой AT+CMGF=0. Память У GSM-модемов есть несколько видов памяти, в которых могут храниться SMS-сообщения. Память модема делится
на три логических секции: первая для просмотра, чтения и удаления сообщений,
вторая для сохранения и отправки исходящих сообщений и третья для только что
полученных сообщений. Обычно модем хранит полученные сообщения в первой
секции. Кроме логического
деления на секции у модема ещё есть несколько видов физической памяти: память
SIM-карты, внутренняя память модема и прочее. Каждая физическая память
назначается определенной логической секции. Таким образом, можно назначить
память SIM-карты для чтения и удаления сообщений, а память модема для
написания и отправки. Каждая область
физической памяти имеет свое имя, для того, чтобы ей можно было оперировать в
командах модема. Вот несколько возможных имен областей: SM – память
SIM-карты; ME – память
модема/телефона; MT – это общая память
SIM-карты и модема, т.е. MT = «SM» + «ME»; BM – память для
широковещательных сообщений сети; SR – память для
отчётов (о доставке и т.п.). Для чтения сообщений
нам понадобится только SM и ME память, либо MT, которая включает в себя и SM,
и ME. Учтите, любое
чтение идёт только из памяти, назначенной для первой секции. Это важно. Для настройки памяти
модема существует специальная AT-команда: AT+CPMS. Формат команды: AT+CPMS=message_storage1[,message_storage2[,message_storage3]] Как видно из формата,
вторую и третью секции памяти указывать не обязательно (они в квадратных
скобках). Поэтому мы их указывать и не будем. Итак. Нам нужно
настроить первую секцию памяти (для чтения и удаления) и назначить ей
соответствующую физическую область памяти. Делается это так: AT+CPMS=”SM”, либо AT+CPMS=”ME”, либо AT+CPMS=”MT”. Первый вариант
указывает на то, что читать будем из SIM карты, второй – из памяти модема, третий
– сразу из обоих. Рекомендую воспользоваться именно третьим вариантом. В ответ на эту
команду модем выдаст нечто вроде (ответ модема выделен жирным шрифтом): AT+CPMS=”MT” +CPMS: 6,100,6,100,0,20 OK Цифры означают
количество сообщений в памяти (например 6) и
максимально допустимое количество сообщений (например 100) в каждой секции. Узнать, какая область назначена для какой
секции можно командой AT+CPMS?: AT+CPMS? +CPMS: ”MT”,6,100,”ME”,6,100,”SM”,0,20 OK Самое главное для
чтения входящих сообщений – это первая секция, на остальные внимания не
обращаем. Чтение Теперь, когда область памяти установлена, можно приступить к чтению сообщения. Для чтения сообщений
существует 2 команды: AT+CMGL и AT+CMGR. Разница их в том, что первая команда
выдаёт сразу все сохраненные в памяти сообщения, а вторая – только одно
сообщение, индекс которого передается ей в параметрах. Индекс начинается с
нуля. AT+CMGL Синтаксис: AT+CMGL=<status> где <status> – статус сообщения в памяти. Возможные статусы:
AT+CMGR Синтаксис: AT+CMGR=<index> где <index> – индекс сохраненного сообщения. AT+CMGL позволят
получить сразу все сообщения, причем можно выбрать по статусу — какие
именно сообщения нас интересуют. AT+CMGR просто выдает нам указанное
сообщение, невзирая на статус. Но нужно знать индекс сообщения. В общем, в примере
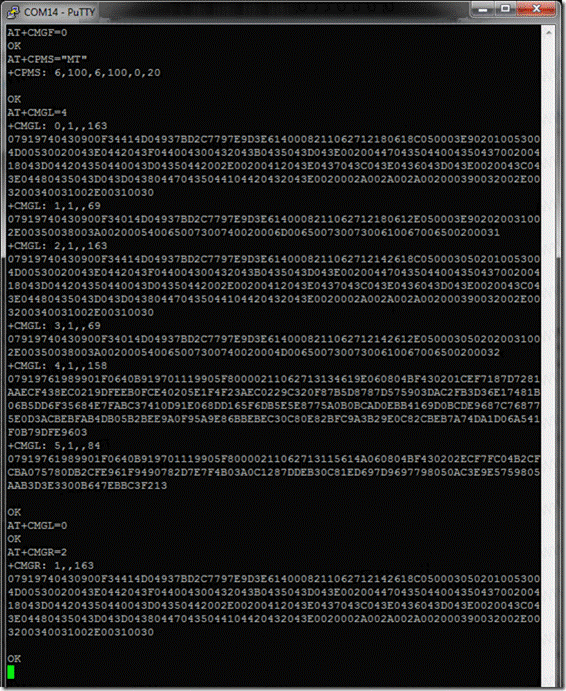
ниже, я использовал AT+CMGL=4 чтобы получить все
сообщения, AT+CMGL=0 чтобы получить только непрочитанные и AT+CMGR=2 чтобы
получить сообщение с индексом 2:
Пояснения к примеру: AT+CMGF=0 – переходим в PDU режим; AT+CPMS=”MT” – переключаем память SIM и модема
на чтение сообщений; AT+CMGL=4 – читаем все сообщения. Модем
возвращает нам всё содержимое памяти МТ. Формат такой: каждое сообщение
начинается строкой +CMGL
с параметрами: 1.
Индекс сообщения; 2.
Статус сообщения (1 = «REC READ», прочитано); 3.
<alpha> – строковый параметр,
определяющий ; 4.
Длина сообщения. Со следующей строки
начинается, собственно, само сообщение в PDU формате. На рисунке терминал
вывел его в несколько строк,
хотя на самом деле модем передаёт его одной строкой. Вот это самое сообщение
мы и будем декодировать. Следующее сообщение опять начинается строкой +CMGL и т.п. Идём далее. AT+CMGL=0 – читаем сообщения со статусом
«REC UNREAD», т.е. непрочтённые. Здесь модем вернул
просто ОК – это значит, что непрочтённых сообщений
нет. Если бы были – он бы их вывел в том же формате, что и до этого. AT+CMGR=2 – получение сообщения с индексом
2. Ответ начинается с +CMGR
и параметров: 1.
Статус сообщения (1 = «REC READ», прочитано); 2.
<alpha> – строковый параметр,
определяющий; 3.
Длина сообщения. И со следующей строки
опять-таки идёт PDU. Примечание: указанные параметры команд и ответов на команды
справедливы, только если включен PDU-режим командой AT+CMGF=0. Если модем работает в
текстовом режиме, то параметры команд и возвращаемый ими результат отличаются
от вышесказанного. Как видим, сложного
ничего нет, приступаем к декодированию текста сообщения. Разбор
PDU
Итак, считывать из
модема сообщения научились, теперь будем их декодировать. Начнём с простого.
Возьмём для примера такое сообщение: 07919761989901F0040B919701119905F80000211062320150610CC8329BFD065DDF72363904 Что в переводе на
русский язык означает «Hello World!».
Разберём его по косточкам:
TP-SCA (Service
Centre Address) – адрес сервис-центра,
отправившего сообщение. Это поле полностью совпадает по своему значению с аналогичным полем
передаваемого SMS, но в
случае приёма сообщений мало чем может нам
пригодиться. Но для проформы мы всё-таки разберём данное поле: первый байт
(07) – длина номера, в данном случае длина равна 7 байт. Следующий байт (91)
– тип номера, в данном случае 91 – международный. Следующие
6 байт – сам номер сервис-центра, дополненный до
четности символом F и переставленными местами парами цифр. Подробнее
об этом изложено в статье про отправку SMS. PDU-Type (PDU Type) –
важный байт типа сообщения, состоящий из различных флагов, разберём его
состав подробнее:
TP-MTI – эти два бита определяют тип SMS. Причём трактовка этих битов зависит от «направления» SMS, т.е. от того, отправляется она или принимается. Вот табличка, описывающая доступные типы сообщения:
В нашем случае,
используется направление Сервис-Центр –> модем, т.к. мы принимаем сообщение.
В нашем примере байт PDU-Type равен 04, следовательно
Бит 1 = 0 и Бит 0 = 0, значит тип сообщения – SMS-DELIVER. Так и должно быть. TP-MMS (More Messages to Send) —
этот бит информирует принимающую сторону, есть ли ещё сообщения, ожидающие в сервис-центре. Если бит равен
нулю, то это значит, что в сервис-центре есть ещё
сообщения для доставки. Если 1 — значит в сервис-центре больше сообщений нет. В нашем случае
этот бит равен 1, значит в сервис-центре
больше нет сообщений для нашей SIM-карты. TP-SRI (Status Report Indication) — этот
бит показывает, будет ли отправлен отчёт о состоянии отправителю. 0 — не
будет, 1 — будет. Этот бит относится к биту TP-SRR (Status
Report Request) в байте
SMS-SUBMIT при отправке. Для чтения сообщения он не пригодится. TP-UDHI (User Data header Indicator) —
этот бит показывает, что содержит блок TP-UD (User Data). Если бит равен 1 —
то блок User Data
содержит ещё и блок User Data
Header, в добавок к сообщению. Если ноль — то
блок User Data содержит
только сообщение. Для нас это важный бит, поскольку дополнительный блок User Data Header
применяется для длинных SMS, в нём содержится информация о количестве частей
в SMS и номер текущей части. Передача длинных SMS подробно описана в «Отправка длинных SMS в формате PDU». TP-RP (Reply Path) — путь для ответа. Это бит говорит, что от
принимающего запрашивается ответ. Если путь ответа запрашивается, отвечающее
мобильное устройство может попытаться использовать тот же сервис-центр, что и
отправитель, для более надёжной доставки ответа: 1 — запрашивается,
0 — не запрашивается Возвращаясь к нашему примеру и учитывая
вышесказанное, анализ байта TP-MTI (04) говорит нам о том, что это принятое
SMS (TP-MTI=0,0 — SMS-DELIVER), что на станции больше нет для нас
сообщений (TP-MMS=1) и что это одиночная SMS, а не часть длинной (TP-UDHI=0). TP-OA (Originator Address)
– адрес отправителя сообщения. Это поле составное:
Длина номера
отправителя в нашем случае 0Bh, формат номера - 91h. Длина номера: указывается количество цифр в номере, если это обычный номер
телефона или количество полубайт,
если это текстовый формат номера в 7-битной кодировке. Формат номера. Тут тоже не все так просто:
Рассмотрим тип
номера:
Нас интересует всего
2 типа номера: 001 и 101, остальное
в основном либо не применяется, либо применяется очень редко. Далее —
идентификатор плана нумерации. Применяется для типов номеров 000, 001, 010 и
101. Нет смысла рассматривать всё, так как в сотовых сетях применяется всего
2 плана:
1. Для типа номера 101
(буквенно-цифровой) идентификатор плана нумерации всегда 0000;
2. Для остальных типов идентификатор
плана нумерации всегда 0001. Непосредственно
сам номер —
может быть двух видов, либо набор цифр, например “ Цифровой номер
кодируется по стандартной схеме кодирования номеров, о ней можно прочитать в
материале «Отправка коротких
SMS в формате PDU». Текстовый номер –
просто строка текста, сжатая в 7-битную кодировку. Как уже говорилось,
длина номера – это либо количество цифр, либо количество полубайт. Т.е. для
номера 79101234567 длина будет равна 11 (0Bh, как в примере), а для номера “InternetSMS” – 20 (14h). Почему 20? Потому, что «InternetSMS» (без пробела) это 11 символов. В 7-битной
кодировке они упакуются в 11*0.875 = 9.625 байт. Умножаем на 2 чтобы получить полубайты, получаем 19.25. Округляем в
большую сторону, т.е. в 20 полубайт. Для ясности, разберём
ещё один пример с текстовым номером: 09D0D432BB2C03. Здесь 09h — длина (9 полубайт), D0h — формат номера. А
дальше — сам номер (длиной 5 байт, т.е. 10 полубайт!). По нормальному
это «Tele2» - 5 символов. При кодировании получается 5*0.875 = 4.375.
Умножаем на 2 чтобы получить полубайты, получаем
8.75. Округляем в большую сторону — 9 полубайт. Но полубайтами мы не
оперируем, поэтому номер в действительности не 9, а 10 полубайт, т.е. 5 байт. Тут настало время
сделать небольшое отступление. Строго говоря, текстовый номер передаётся
вовсе не в кодировке ASCII, как может показаться, а в
специальной кодировке GSM 03.38. Эта кодировка во многом схожа с кодировкой ASCII за небольшим исключением:
латинские буквы, цифры, пробел и часть спецсимволов находятся на тех же самых
позициях, а вот некоторые символы находятся не на привычном месте. Самый
яркий пример - символ «@» с
кодом 00h. Нет также некоторых
спецсимволов вроде [,
], {, }, ~, |, но зато присутствуют символы греческого
алфавита. Кодировка GSM 03.38:
В таблице жёлтым цветом
выделены следующие управляющие коды: LF (0Ah) – перевод строки; CR (0Dh) – возврат каретки; ESC (1Bh) – управляющий символ «Отказ»; SP (20h) – пробел; FF (1Bh + 0Ah) – смена листа, может заменять собой символ LF; CR2 (1Bh + 0Dh) – управляющий символ, зарезервированный для
дальнейшего развития таблицы; SS2 (1Bh + 1Bh) – управляющий символ,
зарезервированный для дальнейшего развития таблицы. А как же тильды с
обратными слешами, квадратные и фигурные скобки? Всё очень просто - для этого
используются Escape-последовательности и каждый такой
символ на самом деле состоит из двух. Например,
символ «{» выглядит как <ESC> + «(», т.е. 1Bh
+ 28h. Всё выше сказанное
относится не только к символьному номеру источника SMS, но и к тексту самой SMS, если она закодирована не в Unicode. Подробнее о кодировке GSM 03.38 можно прочитать на Wikipedia: http://en.wikipedia.org/wiki/GSM_03.38 Итак, вернёмся к нашему примеру: у нас поле TP-OA = «0B 91
9701119905F8». 0Bh – в
номере 11 цифр или символов, 91 — международный формат номера. Далее
идёт «9701119905F8» – непосредственно сам номер. Пары переставлены местами,
номер дополнен до чётного количества символом F, всё по схеме кодирования
номера. Получается, номер отправителя 7-910-119-95-08. TP-PID (Protocol
identifier) – идентификатор протокола. В случае
отправки SMS с телефона/модема на телефон/модем
данный байт всегда будет равен 00.
Для тех, кому интересно, что же это поле означает, могу ответить, что оно
описывает высокоуровневые протоколы или сетевые устройства, куда должна быть
отправлена, или откуда пришла SMS. Другими словами, Сервисный Центр оператора
сотовой связи может поддерживать дополнительные услуги, такие как
конвертирование SMS в e-mail, отправка SMS на
пейджер, телекс. В этом случае данное поле указывает на что-то типа шлюза,
через который пойдет SMS дальше и превратится уже не в SMS
а во что-то другое. Нам это поле не нужно, поэтому оно, как и положено, равно 00h. TP-DCS (Data coding scheme) – схема
кодирования данных. Описывает, как закодирована наша
SMS, т.е. поле TP-UD. Опишу только то, что нам пригодится: 00h — 7-битная сжатая кодировка;
04h – 8-битная кодировка; 08 — UCS2 (Unicode); 10, 14 и 18 — то же,
только сообщение класса 0, т.е. Flash, сразу
появляющееся на экране мобильного устройства. TP-DCS в нашем примере равно 00h, что означает простое сообщение в 7-битной кодировке. TP-SCTS (The
service centre time stamp) – штамп времени сервисного центра. Проще говоря, это время, когда сервис-центр получил SMS,
т.е. время отправки. Данное поле составляет 7 байт, которые
означают следующее:
Причём в каждом байте
цифры переставлены местами, как и в номерах сервисного центра и отправителя. Применительно к нашему сообщению данное поле можно декодировать так: 21106232015061
= Год: 12, Месяц: 01, День: 26, Час: 32, Минута: 01, Секунда: 05, Временная
зона: 16. TP-UDL (User Data Length) — длина
пользовательских данных, включая User Data header, если он есть. Если
SMS закодирована 7-битной кодировкой, то данное поле
указывает количество символов в сообщении. Если кодировка UCS2 – то поле
указывает количество байт в сообщении. В нашем примере TP-UDL равно 0Ch, т.е. 12 в десятичном счислении. Поскольку TP-DCS в нашем примере
равно 00h, что
означает простое сообщение в 7-битной кодировке, то сообщение содержит 12
символов. Так и есть, в сообщении “Hello World!” 12 символов. Однако если посчитать количество
байт сообщения (поле TP-UD), то их будет 11 а не 12,
сказывается сжатие при 7-битной кодировке. Этот момент важно учитывать. TP-UD (User Data) – поле пользовательских данных. Здесь находится сам
текст сообщения. В случае, если SMS длинная, т.е.
разбита на несколько сообщений, данное поле начинается с заголовка TP-UDH. На
наличие этого заголовка указывает бит TP-UDHI поля PDU-Type. По поводу поля TP-UDH подробно
описано в «Отправка длинных SMS
в формате PDU». У нас TP-UD = “C8329BFD065DDF72363904”, что после декодирования
7-битной кодировки даёт нам искомое “Hello World!”. По материалам сайта www.hardisoft.ru Главная / Получение и
декодирование SMS |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||